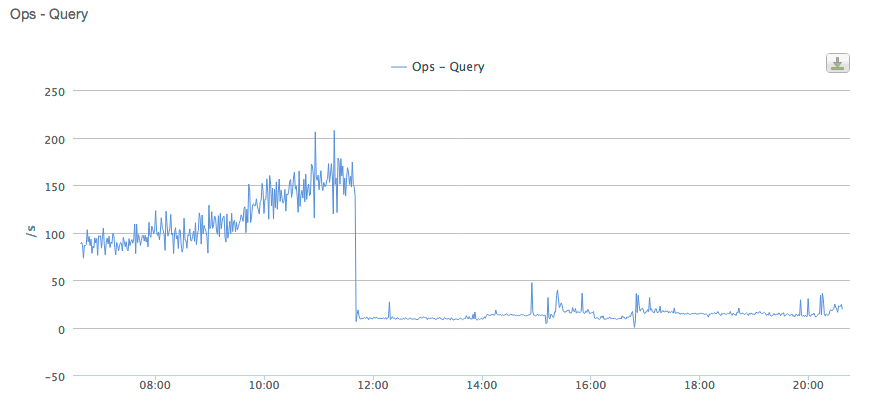
Recently we noticed that our database was doing a lot of queries while processing our queue. Lets see if we can fix that.
Our background worker was looping through a given list of items and for each item it performed several MongoDB queries.
It generated:
- Three finds
- Two upserts
- One set
- One insert
This is six queries per item, where a batch of items consists of 10 to 100 items. This quickly results in a lot of queries!
The class looked something like this:
1class EntryWorker
2 def perform(id, payload)
3 site = Site.find(id)
4
5 payload.entries.each do |entry|
6 ItemProcessor.new(site, entry).process!
7 end
8 end
9endWhere the ItemProcessor does the processing and querying.
To reduce the number of queries we've wrapped the ItemProcessor with a class that tries to cache as much data for queries as possible. Here's a simplified version:
1class EntryWorker
2 def perform(id, payload)
3 site = Site.find(id)
4 @inserts = []
5 @increments = {}
6
7 payload.entries.each do |entry|
8 ItemProcessor.new(site, entry).process!
9 end
10 flush_inserts!
11 flush_increments!
12 end
13endThe ItemProcessor populates the hashes and arrays set by the perform method and when the loop is complete, the data is flushed to the database.
Lets take the increments for example, the data format for this hash is:
1{
2 [bson_id] => {
3 'hits' => 10,
4 'exceptions' => 1,
5 'slow' => 2
6 }
7}
This way we can loop the increments at the end and push them to the database.
1# Pushes the increments to MongoDB
2def flush_incs!
3 @increments do |id, incs|
4 Model.
5 where(:id => id).
6 find_and_modify('$inc' => incs)
7 end
8endSo instead of dozens of upserts that increment a number by 1, we now have a few with the total counts.
Mongoid doesn't support bulk inserts, but the driver it depends on (Moped) does. If we drop down to the collection class we can use that to insert everything at once.
1# Pushes all inserts to MongoDb at once
2def flush_inserts!
3 Model.collection.insert(@inserts)
4endInstead of having hundreds of inserts that take ~ 1ms. We now have one insert that takes only a couple of ms.
We did the same with all the finds,
all the data is fetched before the loop and stored in an array.
We use array.find to select the correct object and use that in the ItemProcessor.
You can see the results below: