


We've been using the combination of Mongodb, Mongoid (3.x.x) and Sidekiq for a while now and we noticed that lately our queue's were filling up, but we could not pin-point any bottlenecks in our system.
The cpu's of our workers were never maxed out, even with a full queue. MongoDB was hardly locked and network traffic was well under the limits.
When tailing the MongoDB logs we noticed that a lot of new connections were made every second. We knew this happened because Sidekiq creates a new connection for each job.
Soon we found out we were not the only ones having this issue. Avi Tzurel wrote a blogpost about this exact same issue and in the comments is a gist that people have found to work.
We've improved it a bit and made it specific for Ruby 2:
1# By default, Sidekiq is going to open a new connection to Mongo for each job and disconnect it afterward because
2# Mongoid stores the session connection on a Fiber-local variable by using Thread.current[]. Inspired by
3# http://avi.io/blog/2013/01/30/problems-with-mongoid-and-sidekiq-brainstorming/, we can override this to put
4# the sessions at a Thread-local variable, not a Fiber local one.
5#
6# TODO Remove when on Mongoid 4, since it uses connection pooling.
7module Celluloid
8 class Thread < ::Thread
9 def []=(key, value)
10 if mongoid_session_key?(key)
11 # In Ruby 2.0, Thread.current[:foo] = "bar" is Fiber-local, whereas
12 # Thread.current.thread_variable_set(:foo, "bar") will be local to the entire Thread and all Fibers running
13 # on it be able to see that variable. As such, storing the Mongoid session on the thread level will let
14 # each Fiber reuse the Mongoid connection: Sidekiq uses Celluloid, which spins up a pool of worker threads
15 # at the designated concurrency level (e.g., by default, Sidekiq uses 25). Celluloid Actors run on those
16 # Threads in Fibers, so each time a Sidekiq job is dispatched to an an Actor, it creates a new Fiber. In doing
17 # this, we have to reconnect to Mongo every single time a job is picked up, and it disconnects when it finishes!
18 #
19 # If you want to see this behavior, an easy way to test it is to create a simple Sidekiq job which just does
20 # something like User.count, then fire up a Sidekiq worker, enqueue a few hundred jobs, and watch Mongo
21 # via mongostat. You'll see connections persist, whereas if you remove this logic, connections will drop
22 # and reconnect each time a job is picked up.
23 thread_variable_set(key, value)
24 else
25 super
26 end
27 end
28
29 def [](key)
30 if mongoid_session_key?(key)
31 thread_variable_get(key)
32 else
33 super
34 end
35 end
36
37 private
38 def mongoid_session_key?(key)
39 # Just put the sessions data at the Thread level; this leaves things like persistence settings, identity map
40 # disabling, etc. to the individual Fiber being managed by Celluloid.
41 return key.to_s() == "[mongoid]:sessions"
42 end
43 end
44endWe decided to take the gist and deploy it to one of our workers to see if it improved job throughput.
Our load balancer devides the incoming requests evenly among our workers. Once we deployed our fix to one of the workers we immediately noticed that it was always done with it's jobs in a fraction of the time the other workers take.
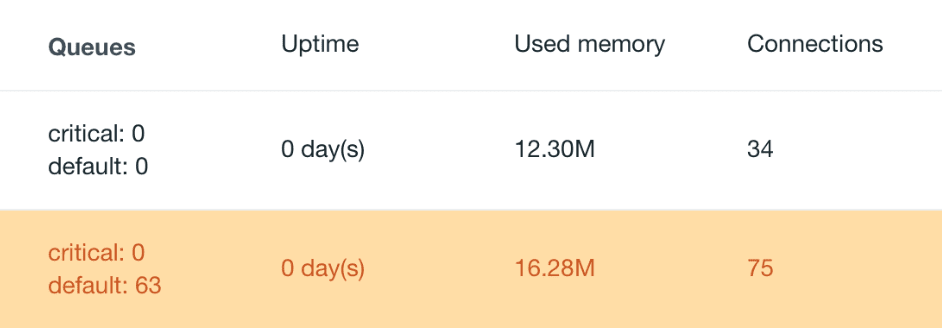
Worker one is already done while worker two has just begun processing.
As an added benefit our MongoDB logfiles are actually readable again since the connection message pollution is gone.
Here's a snapshot of our worker's cpu load, te orange line is the time we deployed this fix.
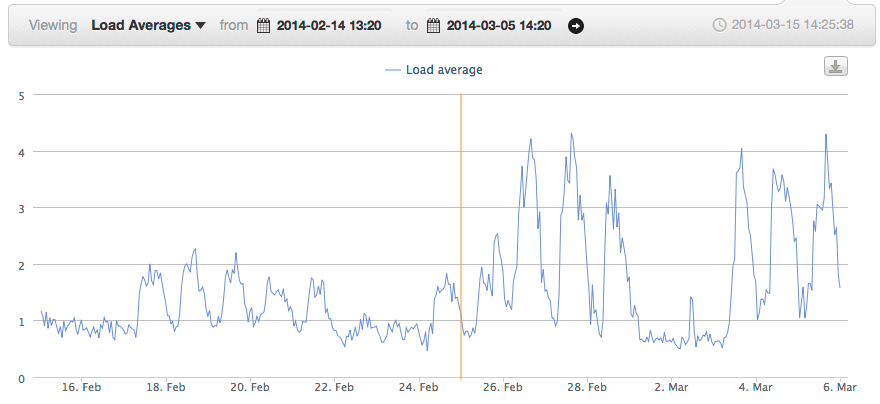
It's been running in production for a few weeks now without any issues.
[note] We're in the process of upgrading to Mongoid 4 and since that uses connection pooling we should be able to remove this patch.



