



In today's post, we'll dive into how we, at AppSignal, solved a daunting engineering challenge. Giving you a look into the kitchen, this post will show you how we tested a new database in production without having to worry about errors/downtime. Alright, let's get cooking!
The Challenge
Introducing a new system in an application stack can be a daunting challenge. To pick the right system, a lot of questions have to be answered. Some of these can't be answered without actually using it in production, but others should be answered prior.
We were looking into a database backend for the new Search feature.
We needed to figure out how to manage backup and restore this database, as well as research what kind of operations were required. But at 100 billion requests monitored every month, we also needed to know how this approach scaled in reality, and most importantly for us, how it performed.
Why You Should Not Use a Staging Environment
Usually, the first step would be to run this new database in our staging environment, but the traffic patterns between staging and production are vastly different. We can't reliably use staging data to extrapolate how it would perform in production.
So, to get a better sense of performance, we ran this new database as a shadow behind our current database with something we call Ghost Queries.
Who you Gonna Call? Ghost Queries!
Ghost Queries are queries that are performed based on real-life production queries, but in such a way that they don't impact production performance or stability.
Here is how we set them up. We created a helper library that wraps the current queries and tracks their performance. After the query has been executed, we place a job on our queue with the query and the "current database" performance.
1result = GhostQuery.track("sample_timeline", sample_timeline_query) do
2 query(sample_timeline_query).to_a
3endIn the background, a worker will then rewrite this query to the new database and execute it. We then track the performance of this new query and we can thus compare it against the old query.
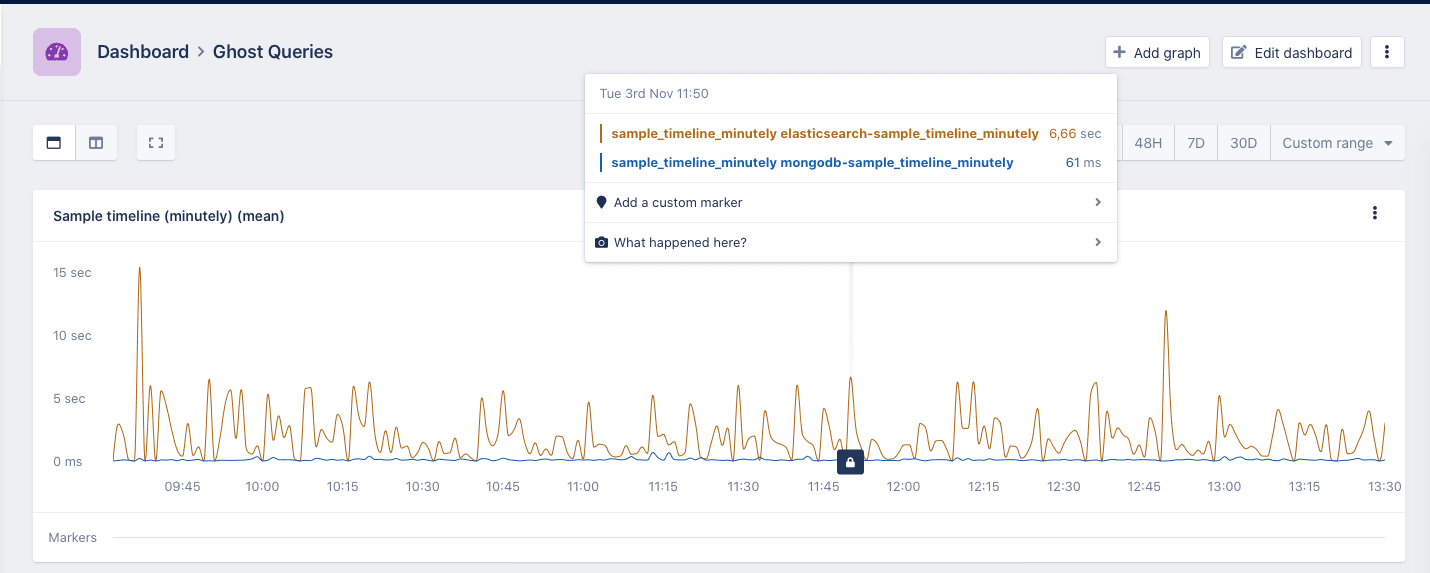
This pattern allowed us to run production load against the new database without worrying about downtime or performance.
More Advantages of Ghost Queries
In addition to tracking real-life performance, ghost queries can answer several of the questions we had before introducing it into our stack. When running the ghost queries, we could check if the returned data matched that of the original query, so we knew we could swap out the database without issues or missing data in the future.
This system also allowed us to perform maintenance tasks under load such as adding/removing nodes from the cluster. It also made it possible to figure out how to backup/restore the data and do test runs of actually doing that. Things that you would ideally practice while the system wasn't in production yet. 🤣
Performance
In our case, the new database performed a lot worse than we'd hoped. Because we used ghost queries, we got actual data about this without the pressure to immediately fix the problem. This gave us time to dive deeper into the issue and try new things without having to worry about uptime.
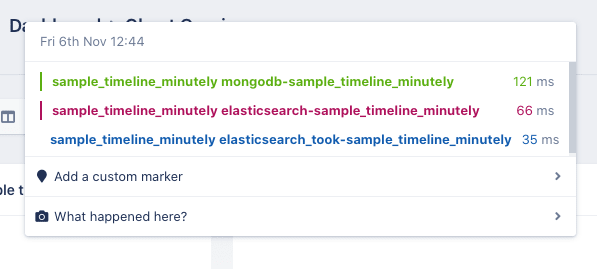
Eventually, we were able to track down a few default settings that did not work for our use-case. We altered these settings, monitored its impact through our ghost query setup, and eventually, it performed way better.
The End Result
With all questions answered, and the setup tested in real life, including adding and removing clusters and backing up and restoring, we switched to the new database. All of this was necessary because the new search feature needed this database setup. With the new feature you can search any incident name, action name or tag values. Also, you can filter to narrow down the results and search on other sample fields.



