



It is incredibly helpful to quickly detect when a customer encounters an error and where the error originated from in your source code. Thankfully, this is where many interpreted languages shine. They always include a complete backtrace — the path where the call was made, which caused the error to be raised (or thrown).
In AppSignal, any error alert will bring you to an incident detail page that shows you that backtrace. With a Github or Gitlab integration, you can immediately jump from an error to the place to solve it.
Beyond that, however, we can make our errors more useful — with a little bit of prose.
The Three Main Questions an Error Message Must Answer
Folks who are old enough will likely remember this screen from the days of old (pre-UNIX) MacOS:
It told us only one thing: your work is over, it's time to reboot the machine. But it took me some time to figure out why this error was so particularly frustrating — it would not answer any of the "big three" questions I believe an error must satisfy:
- What happened?
Not "a catastrophic failure", but what exactly happened? Did the flux capacitor overcombobulate the particle instigator? Was a certain parameter above (or below) an acceptable value? Was a piece of incorrect user input to blame? The error should explain what happened.
- Where did it happen?
Was it QuickTime Player that crashed my machine? Was it this new USB mouse driver that I have just installed?
The error should explain where it originated. Not where it happened exactly in the code — the backtrace usually covers this part — but which high-level component it stems from. If your WindowServer crashes on macOS, it is not that hard to understand that your entire UI has crashed because WindowServer is the process that owns and manages everything on screen. But which application caused WindowServer to crash?
- What can I do to make the error go away?
Did invalid input cause it? Maybe we are trying to access some data that is, for example, no longer available, and we could catch this access attempt at a higher level of the stack? Or maybe we have a client that sends invalid input and always leads to this error? The error should do its best to tell us how to prevent it from happening again.
Item 4 on this list would be "automatic recovery" and it becomes relevant when multiple systems know of the same error semantics and try to recover from them in a distributed way. This can be a great topic for a future article.
Optimizing Your Error for the Reader
Take a look at this error as you would see it in AppSignal:
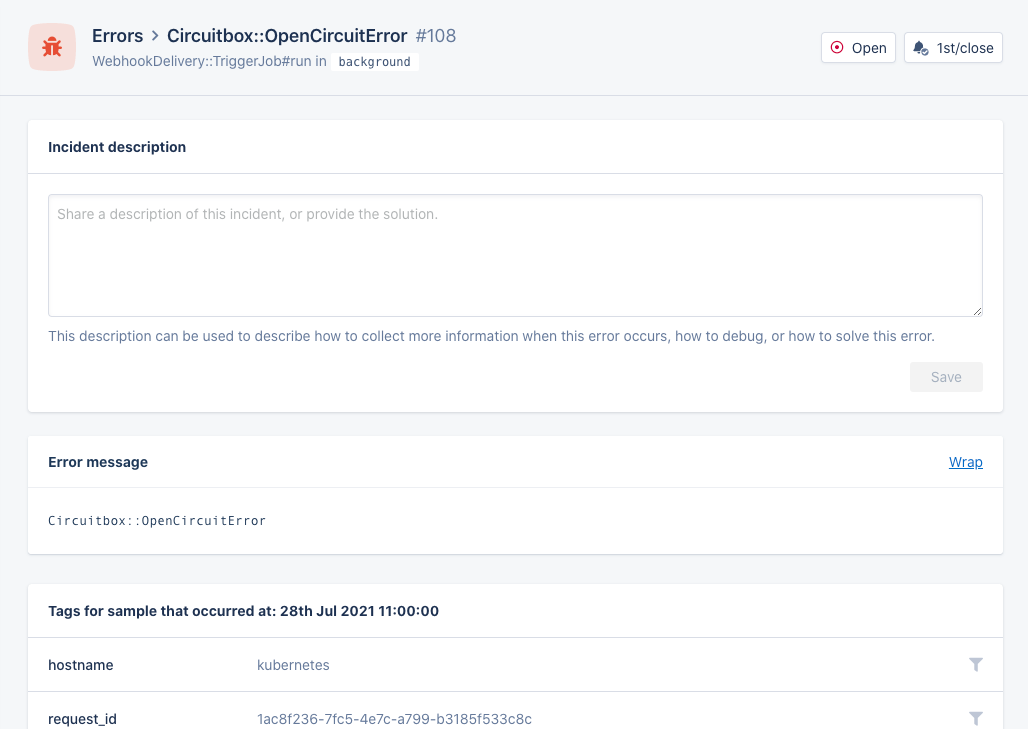
It gets raised by a popular Ruby gem called circuitbox. This gem implements the famous Circuit Breaker pattern in Ruby.
A short summary of what circuit breakers do:
- If you call an external service (a web service API, database, or cloud storage system), your call might fail. If the service you are calling is down for a long time, all of your calls will fail, and you will be bombarding this service with calls and connection attempts.
- To allow your application to proceed regardless — and to avoid the service you are calling from getting overloaded — a so-called "circuit breaker" gets inserted between your application (the caller) and the service your application calls (the callee).
- Should N consecutive calls from the caller to the callee fail, the circuit breaker will "open" and forbid any subsequent calls from going through, failing these calls rapidly.
- After some time, the circuit breaker will attempt to "close" and allow calls through. If the callee has recovered by then, normal operation will resume.
Once you start using multiple services, having a circuit breaker becomes an absolute necessity. Sometimes, you need several circuit breakers — one for each service you call (or for each host you call, depending on the situation). A particular service that you call might be responsive, while another might be having a bad time.
Circuitbox provides such a wrapper, and when a service you are calling isn't working (for some time), the circuit breaker is open. The gem raises an exception to indicate that the call isn't allowed to go through.
Let's examine this error against the "big three" questions I mentioned above:
- What happened?
Well, a call to a service tripped a circuit breaker — some circuit breaker. One could say that this satisfies the What? question, although for me, it would be constructive to know what the originating error was. This error is derived (or a wrapper, if you will). It gets raised once some other error (the one causing the original service failure) happens for some time. That's the error I would expect to see in the message.
- Where did it happen?
The error does have a backtrace, and if we follow it closely, we find some clues as to where it has originated. The application this was lifted from produces a backtrace of 34 levels for this error, and the spot where the circuit breaker is called from is located on line 4.
It does not tell us which service we were calling or how long the service was inoperable. So it certainly does not fulfill the where part and makes investigation harder. What would help is for the error to tell us in which service it originated — what were we calling when it happened?
- What can I do to make the error go away?
This error does not tell us what we can do to re-establish operation. At first glance, it would seem that it never could — a remote service does not respond, nobody knows when it could recover. So, preventing it from happening again seems to be off the table.
But think again: we could know, for example, that the service hasn't responded for 30 seconds, or that it has been down four times in the last 24 hours — which would enable us to contact the service owners and ask them about their SLOs.
More importantly, in this particular case, the error led to a developer attempting to do an incorrect bug fix. This is a fairly real danger for errors that seem severe but do not answer the three main questions. Bear in mind, when you are handling errors, you will often be in a stressful situation. It might be that your application is overloaded and you need to get it fixed quickly. Or it might be that your business depends on this transaction taking place and the circuit breaker is in the hot path of the transaction.
In our specific situation, an engineer attempted to capture all calls and forbid outgoing HTTP requests to a specific hostname because they assumed that the circuit breaker covered calls to all hosts handled by a code path. They did not know that the service name for the circuit breaker was specific to the hostname we were calling and that the circuit breaker tripped for external service A did not mean that it also tripped for service B. This is the price of error messages that are not informative enough.
So, although a circuit breaker is practical, this error message could use some TLC. Let's see where we can make improvements.
Adding More Context to the Error with Heredocs
The first — and easiest — change we can make is to explain the meaning of this error. We start with just the class name. It can be very descriptive — for example, ActiveRecord::RecordNotFound is a reasonably descriptive class name for an exception. Circuitbox::CircuitOpen is pretty good in that regard — it does communicate the error condition to us.
The next part to look at is the error message. When you initialize an object that subclasses Exception in Ruby, you can pass a data string to include as the error message. The message is then available under the Exception#message method:
1raise ServiceUnavailable, "The service you were trying to call was unavailable"`Let's apply those patterns to our open circuit message:
1raise CircuitOpen, <<~EOM
2 The circuit breaker is open. This means that the service you are calling has been unavailable or has been timing out
3 for some time, and the circuit breaker has opened to prevent your application from slowing down and to protect the
4 service you are calling from the thundering herd of requests once it recovers.
5EOM
This gets us a notch closer to fulfilling question 1 — telling what happened. Now the error will be understandable for someone who doesn't know what the circuitbox gem does or what its various exceptions mean. This speeds up debugging. But we can still take this further!
Taking It a Notch Further with Dynamic Data
For some inspiration, we can look at ActiveRecord::RecordNotFound error message:
1Couldn't find Batch with 'id'=14082This error message communicates a few crucial bits of information, namely:
- Which model we were trying to find (in this case,
Batch) - Which row we were looking for (in this case, the row with the
idof14082)
This gets us way closer to fulfilling the second and third questions. It tells us where it happened (somewhere where we were looking for a Batch with the id of 14082) but also, to an extent, what we can do to prevent it from happening again. We need to find where code similar to this gets executed in one of our backtrace lines or close to them:
1Batch.find(id)But if we look at other examples from Rails, we can see some more useful error messages there. For example, the famous "whiny nil" extension tells you when you mistakenly try to obtain the id of a nil value:
1Called id for nil, which would mistakenly be 4 -- if you really wanted
2the id of nil, use object_idWe are not limited to specifying the error messages with single-line strings, we can also use heredocs - a multiline string preformatted with line breaks. While quite a few people use heredocs in Ruby, there is one feature in them that often gets forgotten, namely, heredocs support the same string templating as double-quoted strings do! So, just as we can do this:
1raise CircuitOpen, "Service #{@service} was unresponsive"we can do the same in a longer chunk of text with a heredoc:
1raise CircuitOpen, <<~EOM
2 The circuit breaker for the service #{@service.inspect} is open.
3
4 This means that the service you are calling has been unavailable or has been timing out
5 for some time, and the circuit breaker has opened to prevent your application from slowing down, as well as to protect the
6 service you are calling from the thundering herd of requests once it recovers.
7EOM
Note how I use inspect for the string templating so that the literal value of a variable is automatically
displayed in quotes and is visually separated (delimited) from the rest of the message. This makes it easier to distinguish
the dynamically generated part of the message from the written prose.
Enhancing the Display with Structured Data
Often, errors are caused by specific user input. Since we can include arbitrary programmatic strings in our error messages, nothing prevents us from having relevant user input in the error message (if we know that input can be useful). We can make this input fit for human consumption using something like JSON.pretty_generate:
1raise MyError, <<~EOM
2 Fields were provided for validation which didn't match the schema. The input was:
3
4 #{JSON.pretty_generate(params[:transaction_details]}
5EOM
For example, in one of WeTransfer's applications, we have a well-known failure condition that creates a specific pattern of invalid input. Since we know this error only emerges in the face of that input, we inject it into the error message. Here's what that error message in AppSignal then looks like:
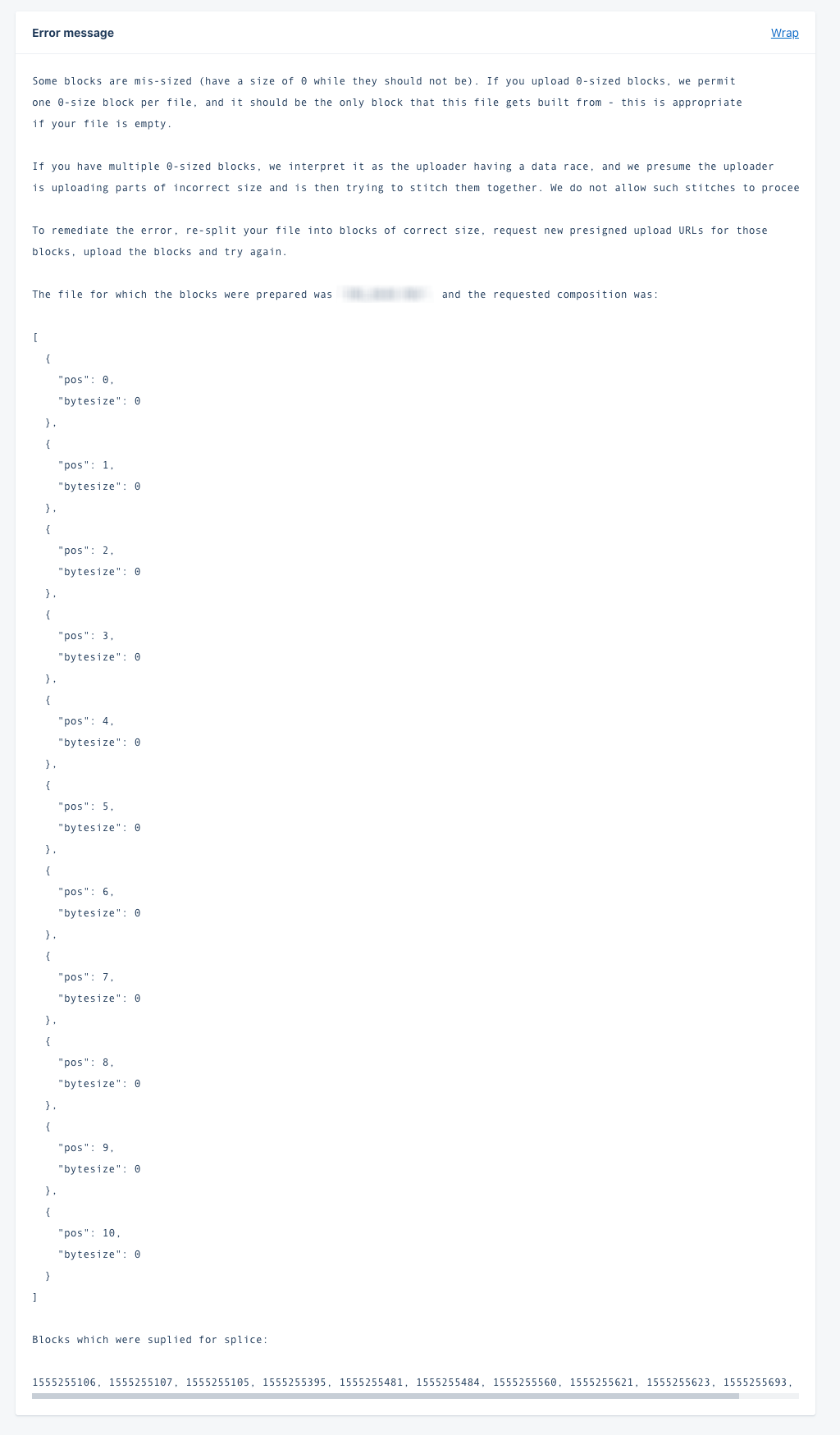
Be careful with that pattern though: the data inside your exception message is subject to data protection laws, just like any other personally identifiable information.
If you do template your input into the error messages, you might need to ensure that you are permitted to send it to services such as AppSignal. As the data is inside the error message, it can no longer be automatically anonymized or scrubbed.
Conclusion: The What, Where, and Why of Errors
You want your errors to tell you what happens, where and why they happen, in a form that requires as little investigation as possible.
Long error messages are a great way to achieve that and provide you with considerable benefits at a small up-front cost. Just write that error message!
WeTransfer is one of our long-time users. Read more about the smart ways they've used AppSignal in our case study.



