



It's important to be able to look at the entirety of your application architecture, not just specific aspects of it, and understand how different parts connect. Observability comes first, followed by monitoring.
In this post, we'll dive into the database part of your architecture to show how you can monitor and optimize your database performance. Most of the following principles apply, regardless of your stack, or whether you want to monitor and optimize performance for PostgreSQL, MongoDB, or any other database.
Why Monitor Database Performance?
Let's say a query is very slow, and your app has to wait for results - causing things to grind to a halt for your end-users and/or in a part of your app.
Like in a traffic jam, a part might end up standing still as an effect of something taking place elsewhere. If a lot of queries take too long to resolve, this might be because other queries get in the way.
Your goal is to find out where an issue is coming from before things start going wrong in other parts of your app.
The next step is to proactively use monitoring to optimize your architecture and see how you can make things faster. But we are getting ahead of ourselves - let's start with step 1:
Step 1: Measuring AKA Instrumenting Database Performance
Database monitoring begins with making sure you measure the right things:
Errors
Performance
the means and 90th percentiles of queries duration
the total throughput - gives you another way to set triggers/flag when throughput is an issue
Luckily, getting that data has already been done for you: your APM software likely lets you configure what you want to instrument and measure. If you use AppSignal, collecting and aggregating the data happens automatically, without much setup. We've done the heavy lifting for you!
Step 2: A Starting Point - Find High-impact Queries
Once you have your app instrumented and real-world data starts coming through, you'll see patterns emerge. On AppSignal, we've built screens for the slowest API requests and the slowest queries under 'Improve' in the navigation:
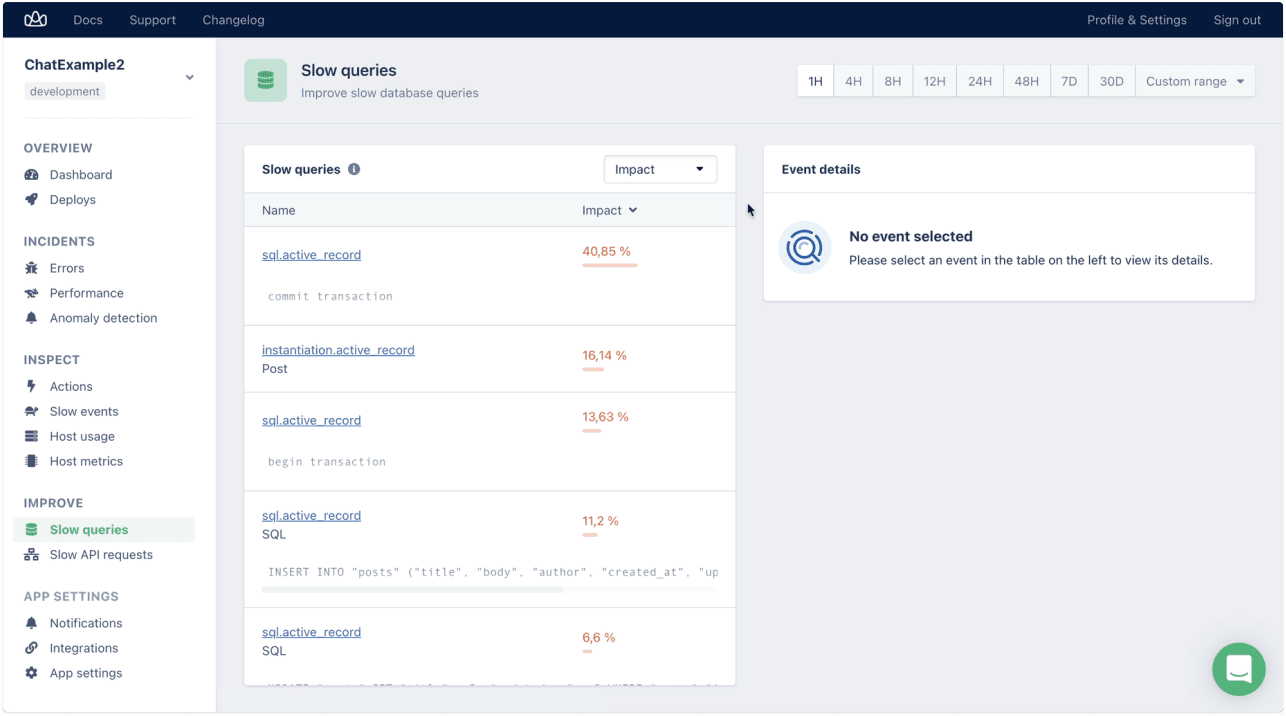
This screen will give you a great starting point for optimization. By default, slow queries are sorted by impact. They are queries that you often do. The impact is the throughput x the mean query time.
Toggling between these sortings will give you an idea of the queries with the most volume, the ones that are the slowest (but are perhaps once-a-night background jobs that you can easily ignore), and those that have the most impact.
A Quick Side-step: Fix Some Individual Queries
Now you can find some queries to dive into fixing.
If you click on a slow query, you will see all of its details on the right, from the throughput and response time for the query to the query name itself:
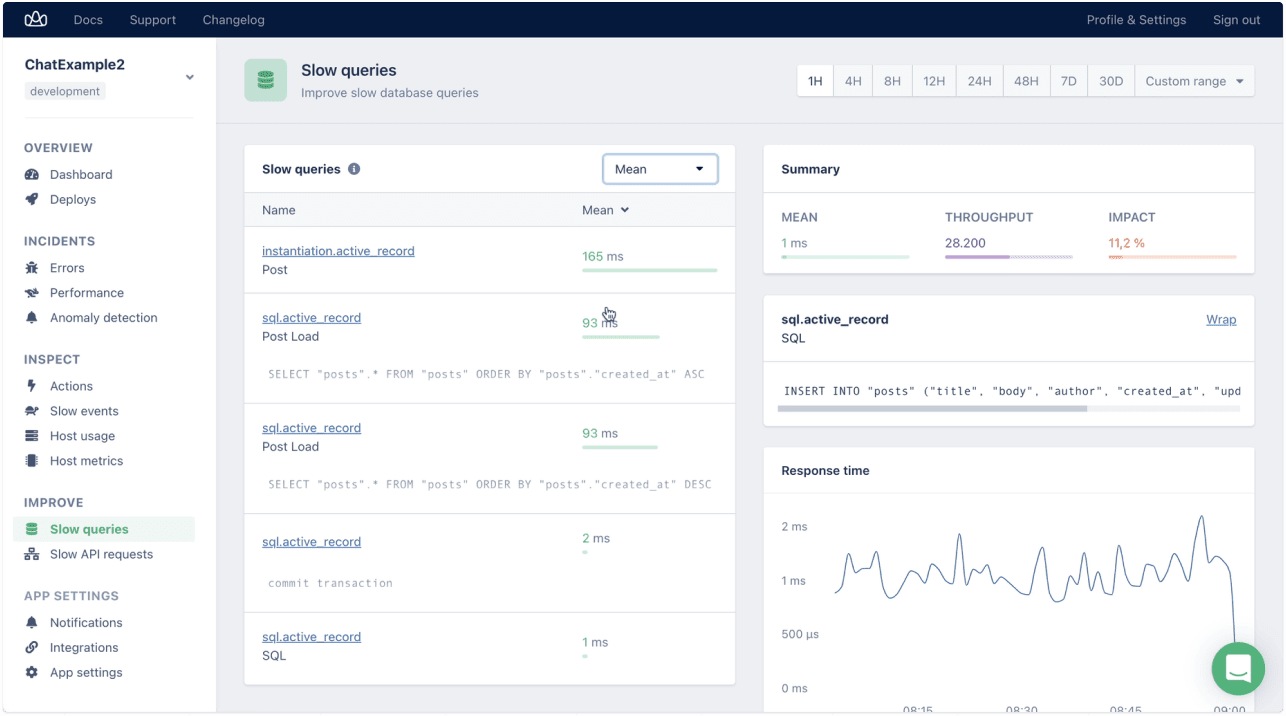
Hover over the response time on a peak, and you can then zoom in by clicking on the 'what happened here' option. You'll see what errors happened at that point in time, in that sample, and what happened on the host.
We've made it very visible for one particular anti-pattern: N+1. The N+1 anti-pattern happens when a query is executed for every result of a previous query.
The query count is N + 1, with N being the number of queries for the initial query results. If that initial query has one result, N+1 = 2. If it has 1,000 results, N+1 = 1,001 queries. Boom.
If queries follow the N+1 anti-pattern, that's a happy accident - they are labeled here so you can quickly find them:
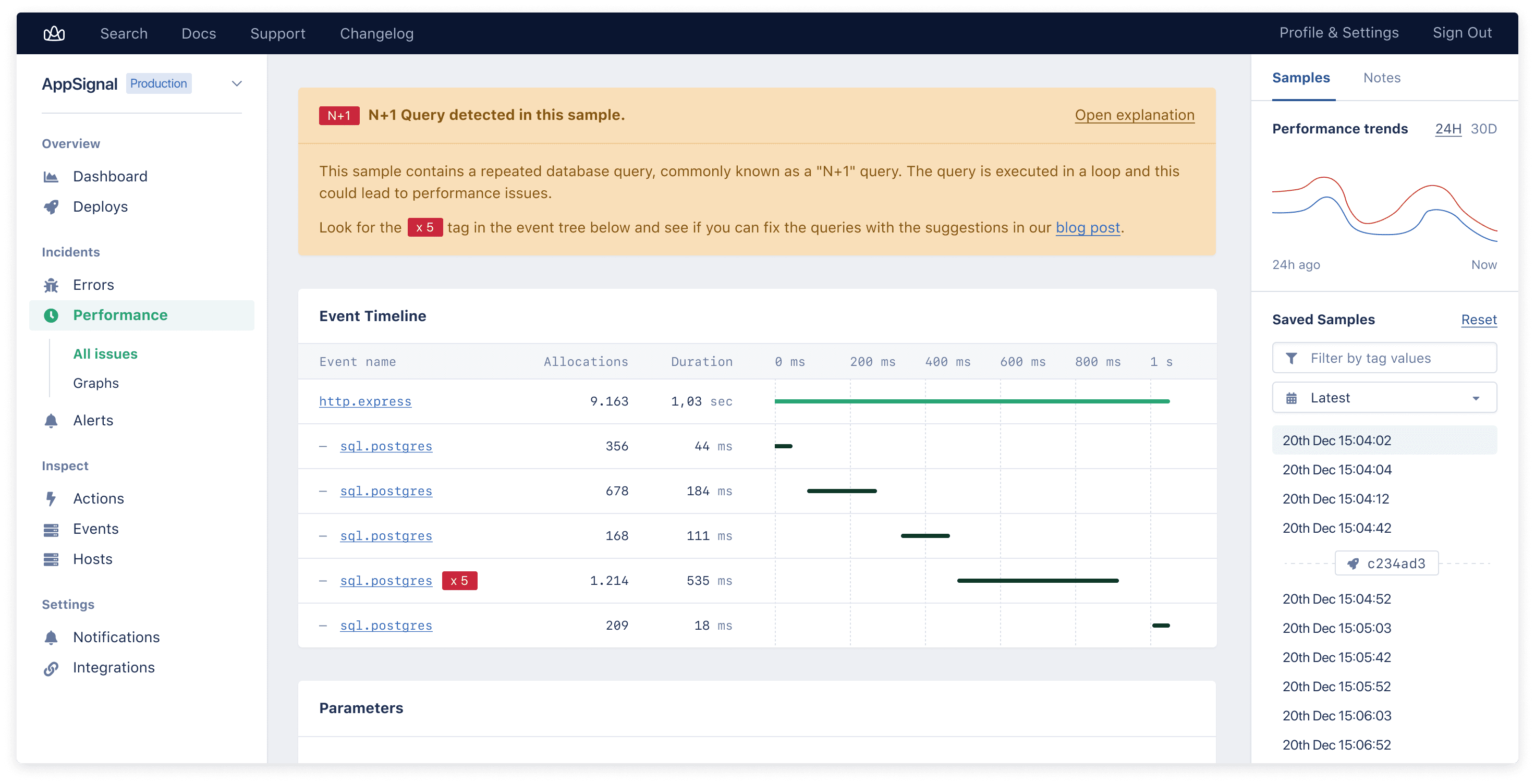
We won't go into how to solve them here - we've written a separate blog post on N+1 queries.
Alright, now let's assume we fixed some crazy things, and as we fixed them, we noticed when they happened and the worst response times.
Step 3: Finding Deciding on Patterns - What Is Wrong?
Monitoring is often about looking at when things go wrong. But part of the complexity around monitoring is defining what should be considered 'wrong' for your setup. Also, would you rather be alerted by an issue that then solves itself or miss one that doesn't?
Let's look at the throughput and duration of your queries on average. You will be able to set that up on your APM software. If you're using AppSignal to monitor Node.js and use PostgreSQL as your database, we automatically create dashboards with the most important metrics for you.
The node-postgres dashboard will show data like this:
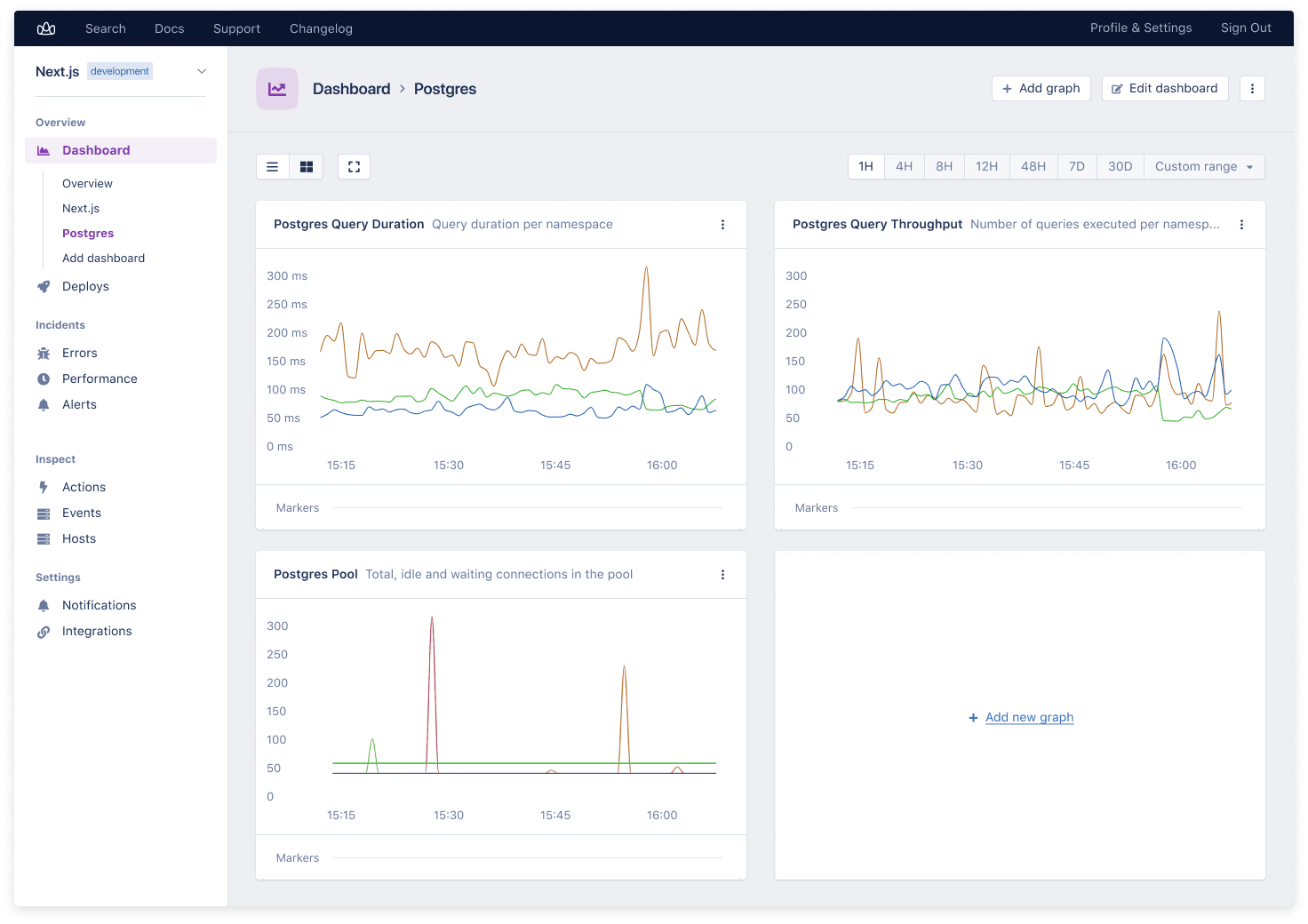
If you'd like to set this up for your app, here's some further reading.
When you switch between different time ranges, you will see short peaks that disappear in the average of an hour, as well as peaks that stay high when you zoom out to a more extended time range.
From our experience of having seen the slowest query screen, we now have an idea about the main culprits and when they peaked.
Certain short peaks in throughput might be fine - the host might be running other processes that make a query slow, for example.
You'll want to zoom into prolonged longer query times or peaking throughputs. Looking at the 95th percentile versus the mean can tell you if a slower query is being experienced by everyone or only by a small subset, which can sometimes help point you towards what to fix.
Step 4: What Should Keep Get You up at Night?
We usually recommend starting on the noisy side of the spectrum: set some triggers to alert you on a channel that doesn't wake you up, like email or Slack, rather than PagerDuty.
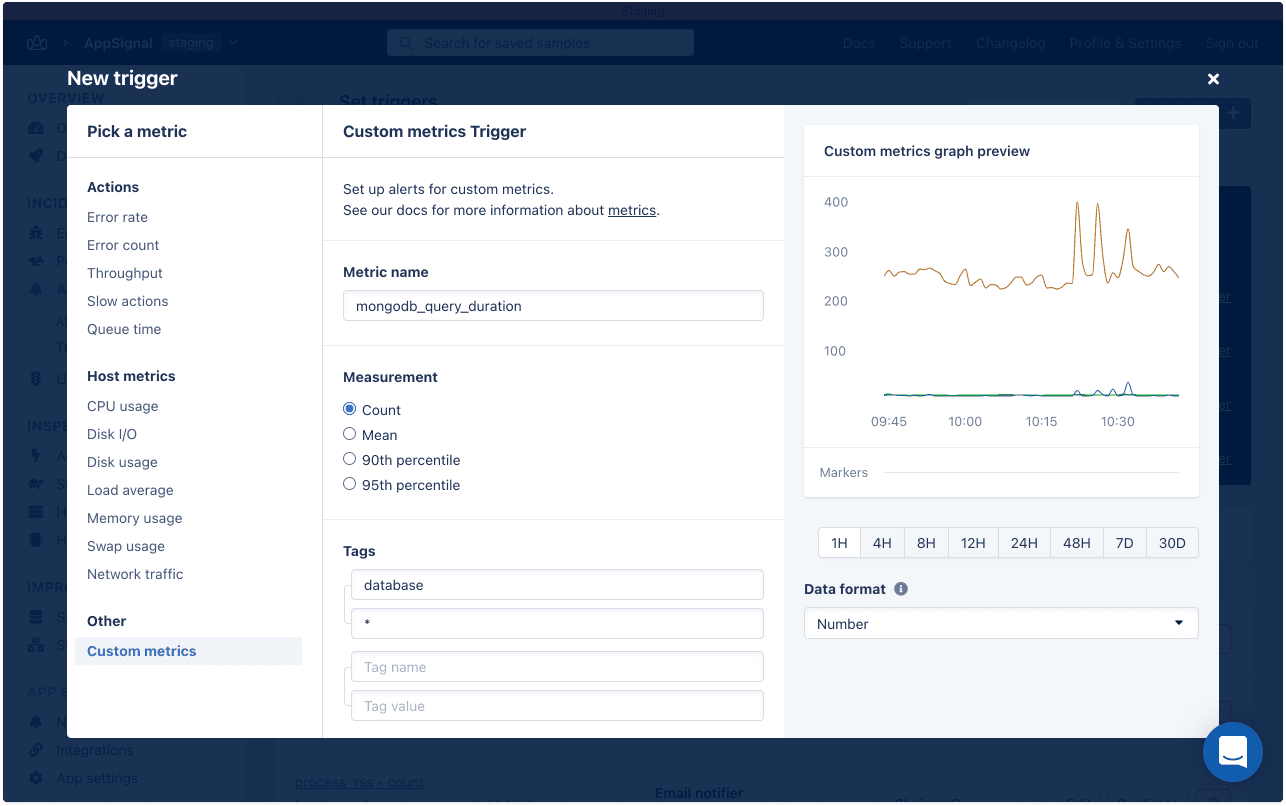
Create a custom metrics trigger on the "event_duration" metric and select the mean field to get an alert on average query time in your app. Select 90th or 95th percentile to get alerts on the slowest queries your app encounters.
Then configure the "group" and "namespace" tags for the type of event you want to be alerted about and in which namespace. For example, "active_record" (Rails) or "postgres" (Node.js) or "ecto" (Elixir) for the group, and "web" or "background" for the namespace:
After a week, you'll start seeing some patterns and get an idea of which cases require your attention and which cases usually solve themselves.
You can then adjust the triggers to be less noisy and add channels for when you want to be woken up by specific alerts.
Step 5: Done with Setting Up Database Monitoring
Now, in theory, we should have a nice monitoring setup: the right data comes in, we've set triggers to warn us before the bits hit the fan, and we've found some big culprits. We should be done, right?
In reality, usage of your app might grow and create new bottlenecks. Or code changes may hit your database, causing the duration to go up. Or a particular field with a huge payload will trigger something. However experienced you are, new problems and bottlenecks will occur.
But you can find comfort in the fact that, with the proper setup, you will be warned and know how to dive deep into your architecture to solve these issues.
And perhaps you can find joy in improving the big 'impactful' queries before any other screws come loose. It's what we love best - that, and stroopwafels.
Try AppSignal, Get Stroopwafels 🍪
Speaking of stroopwafels, we send them all over the world. Give our AppSignal APM software for Ruby, Elixir and Node.js a try. If you set up a free trial and reach out to us, we'll send you a box of stroopwafels on the house.








