



In this article, I will describe the roles and implementation of aggregates in Elixir and PostgreSQL. We'll learn:
- what domain invariants are
- how to use aggregates to protect them
- what to pay attention to when choosing a specific implementation for your aggregates
- why domain knowledge is essential when designing suitable aggregates
We have a lot of ground to cover, so let's dive right in!
What Are Domain Invariants?
Let’s start by looking at a core concept: domain invariants. A domain invariant is a fact that always has to be true in your business domain. Here are some examples:
- In an e-commerce platform, a cart's total has to be the sum of all product prices and applied discounts.
- In a booking application, a room cannot be booked by two different people at the same time.
- In accounting software, the current account balance has to be the sum of all the transactions and a withdrawal cannot be made when the balance is below 0.
- With a carpooling app, there can be a max of X people in the car (where X is the maximum capacity of the car).
Aggregates Protect Invariants
Now let's look at aggregates. The job of an aggregate is to protect the invariants for a given entity or group of entities.
Let's continue with the example of the carpooling application. One of our invariants is that the number of people who sign up for a ride should never exceed the number of seats:
1defmodule Ride do
2 def book(ride_id, passenger_id, now \\ DateTime.utc_now()) do
3 ride = fetch_ride(ride_id)
4
5 if can_add?(ride, passenger_id) do
6 passenger = insert_passenger(ride_id, passenger_id)
7 {:ok, ride, passenger}
8 else
9 {:error, :cannot_add}
10 end
11
12 end
13
14 defp can_add?(ride, passenger_id) do
15 # Any conditions we need to check
16 limit_not_exceeded?(ride) && passenger_not_blocked?(ride, passenger)
17 end
18endIf we don't explicitly control concurrency, nothing prevents two different processes from booking the same ride when there's only one seat left:
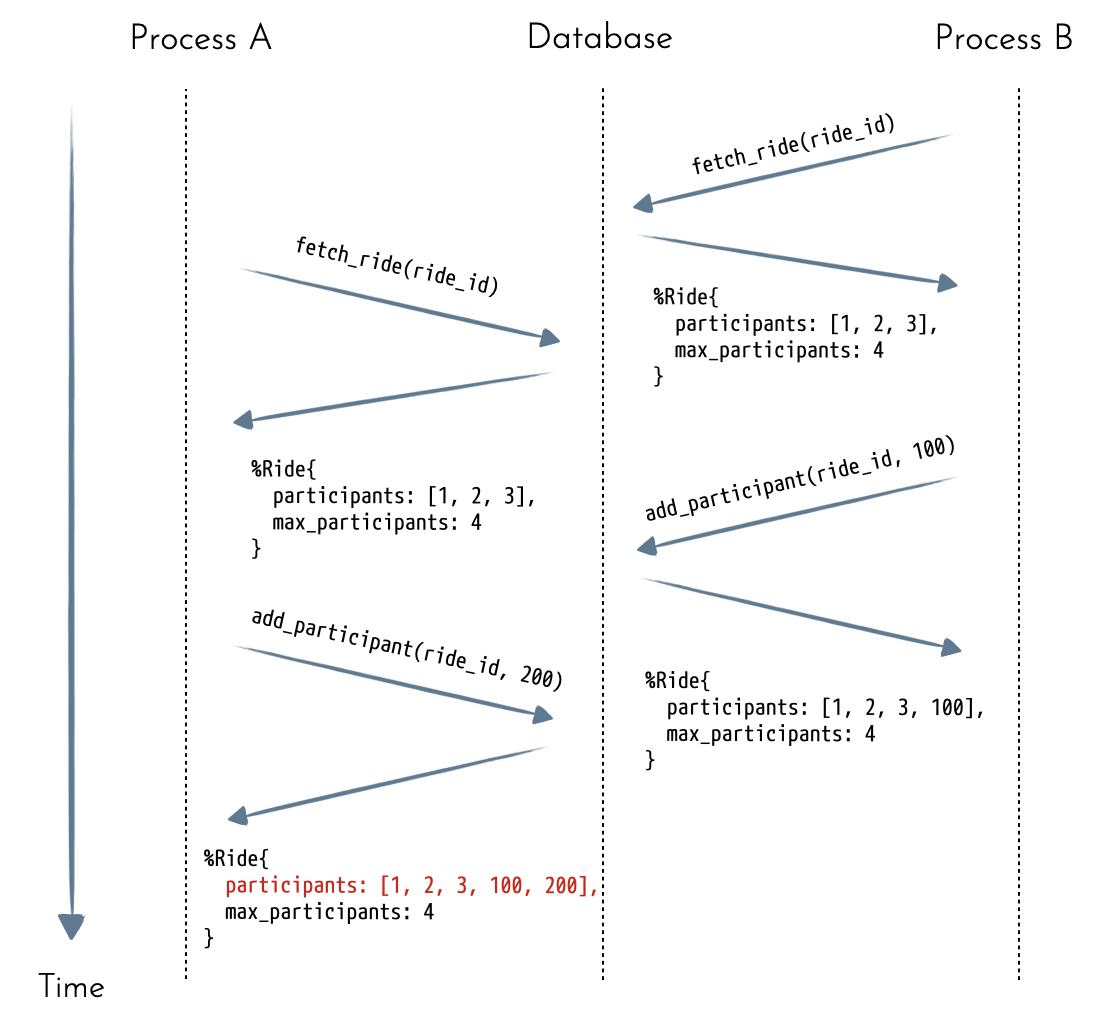
Depending on how we model the data and the updates, we might end up with different results.
If we insert a participant as a new row, we might end up with more participants.
If we keep the list of participants as a list on the
Ride, the participant added by Process B might be overridden by the one added by Process A (which is known as a Lost Update Problem).
There is often more than one invariant that we need to protect. Examples from our carpooling app might include:
- If one user blocks another one, they should not be able to ride in the same car.
- A premium user can choose the front seat if there's no other premium user already booked.
- For multi-stop rides, you cannot add a new stop if it conflicts with the existing route (according to some business rules).
Editing any of the information related to a ride can endanger any of those invariants. That's why we need to have a proper boundary to run all the checks and validations.
The Aggregate and the Root
An aggregate needs to have a required boundary of consistency. Within that boundary, all invariants have to always be true. Every potential update we make to the aggregate should include all the necessary checks.
Typically, we use the aggregate root to help us do that. The aggregate root is the "main" entity of our aggregate.
In our example, the Ride is the aggregate root, while the entire aggregate consists of the Ride and all Participants associated with that ride.
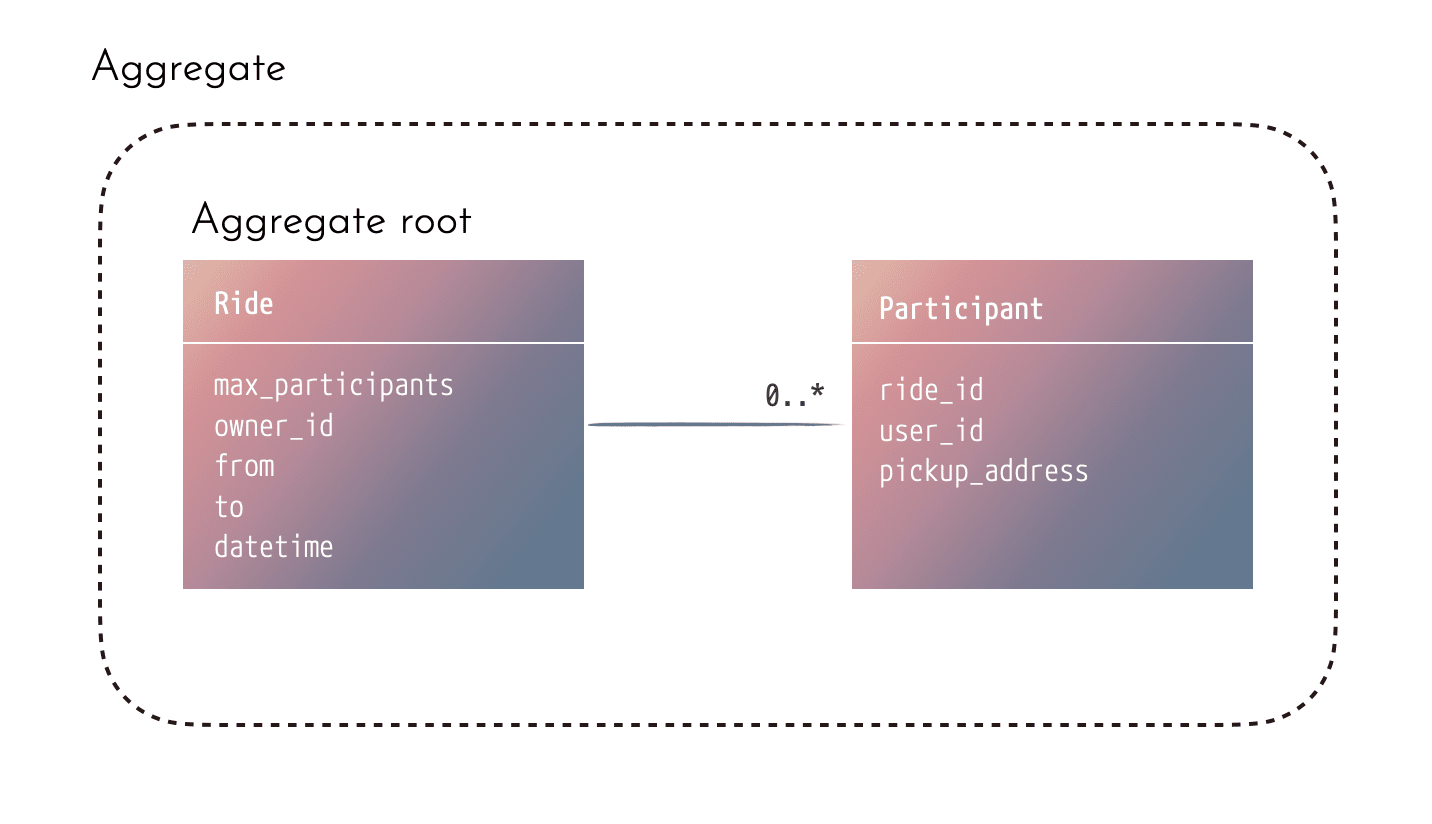
The general rule is that all updates for any entities in the aggregate should go through the aggregate root and validate the invariants across the entire aggregate.
Every update done to one of the aggregate's entities has the potential of breaking one of the invariants. A single path for all the updates allows us to verify all of the changes in a consistent way.
How to Implement Aggregates in Elixir
Our goal is to make sure that all the invariants are true after saving an aggregate.
Since we essentially want to perform proper concurrency control, we need to do the following for every change:
- Make sure no one else can change the resource until we're finished.
- Check all the invariants and rules.
- Make all the necessary changes.
- Allow others to use the resource.
Let's look at some ways of achieving that.
The Process-based Approach
One of the jobs of an aggregate is to prevent conflicting, concurrent updates. In Elixir, we have a tool for that — a process.
A process handles incoming messages sequentially. If we can ensure that a single process does all operations on an aggregate, conflicting updates should not be a problem.
We'll need a way to find a process for each aggregate. Registry is a nice tool for that:
1defmodule Ride do
2 use GenServer
3
4 def start_link([]) do
5 GenServer.start_link(__MODULE__, [], name: get_name(ride_id))
6 end
7
8 def add_passenger(ride_id, passenger_id) do
9 GenServer.call(get_name(ride_id), {:add_passenger, passenger_id})
10 end
11
12 def handle_call({:add_passenger, passenger_id}, _from, state) do
13 # The calls are processed sequentially
14
15 if can_add?(state, passenger_id) do
16 new_state = insert_passenger(state.ride_id, passenger_id)
17 {:reply, ok, new_state}
18 else
19 {:reply, {:error, :no_seats_left}, state}
20 end
21 end
22
23 defp get_name(ride_id) do
24 {:via, Registry, {RideRegistry, {__MODULE__, ride_id}}}
25 end
26endThe biggest issue with the process-based approach is that problems start appearing when we run our code on more than one node.
Registry only runs locally. If two nodes attempt to do operations on the same entity, nothing prevents them from doing so simultaneously.
Solutions like the global registry won't really help, either, since they generally favor availability over consistency. This means that, in the event of node partition (which will happen, sooner or later), two nodes can end up registering their own processes for a specific entity, leading to the same problem as the local registry.
The chances of that happening are lower than with Registry, but it's still not a safe solution.
The Database Approach
We can use a database as a source of truth for our needs. If your database supports locks, you can use that mechanism to prevent concurrent updates.
The necessary steps for updates are:
- Fetch the resource you want to modify using the
FOR UPDATElock. - Verify all the invariants.
- Make updates.
- Release the lock.
Firstly, we need to lock the resource that we're trying to modify. Since there can be another process in the middle of another transaction, we need to make sure that we fetch the latest version of the resource — hence the FOR UPDATE option for the lock.
This guarantees that if there's another process which has already locked that resource, our process will wait for its turn and fetch the most recent, already committed version of that resource:
1defmodule Ride do
2 def add_passenger(ride_id, passenger, now \\ DateTime.utc_now()) do
3 Repo.transaction(fn ->
4 ride =
5 Ride
6 |> lock("FOR UPDATE")
7 |> where(id: ^ride_id)
8 |> Repo.one()
9
10 if can_add?(ride, passenger_id) do
11 passenger = insert_passenger(ride_id, passenger_id)
12 {:ok, ride, passenger}
13 else
14 {:error, :cannot_add}
15 end
16 end)
17 end
18
19 defp can_add?(ride, passenger_id) do
20 # Any conditions we need to check
21 limit_not_exceeded?(ride) && passenger_not_blocked?(ride, passenger)
22 end
23endSince the locks are automatically released once a transaction is committed, we don't need to do that explicitly:
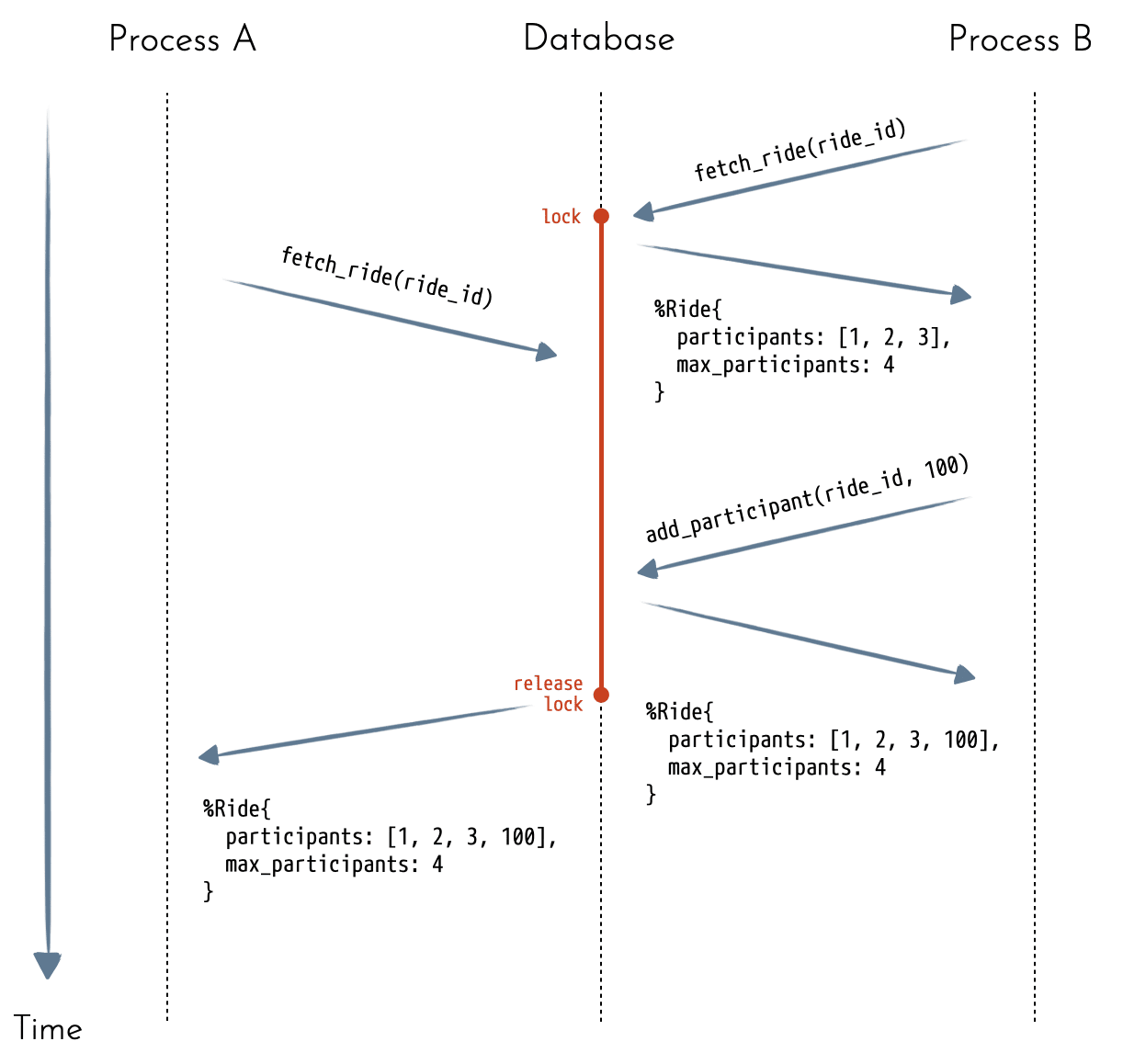
This approach is called pessimistic locking. As the name implies, we want to make sure that nobody else is doing another operation even before we start.
There are some problems with this approach.
First, no matter what the operation is, we have to wait until a lock is released before doing any other work. This can be a problem if the steps necessary to perform the business transaction are long.
If transactions last a long time, and only one can happen at a time, we risk lowering the throughput, increasing the latency, and hurting the user experience.
There's another problem with waiting. Since the lock has to happen inside a database transaction, the process must hold to that transaction for the entire operation. This is a problem because of the limited pool size of database connections. Every process waiting to acquire a lock occupies a connection that could be used for some other query.
Finally, this approach won't easily work for business transactions that span multiple HTTP requests. If the business transaction is more complicated and requires some input from the user, pessimistic locking is probably not a good choice.
We can address these problems by using optimistic locking instead.
Optimistic Version Control
In optimistic locking, you rely on the assumption that no other process will change the aggregate.
Whether that's a safe assumption to make depends on the specific use case. For example, the chances of a conflict are different for an e-commerce system, where a user only operates on their own cart, versus a booking application — where multiple people might want to book a concert ticket at the same time.
Understanding your domain and specific use case is important!
The steps for optimistic locking are as follows:
- You start a transaction and fetch the resource without locking it.
- You verify all the constraints and do all the work without actually committing the changes.
- Just before you commit, you lock the resource and verify if the version hasn't changed (which would mean that some other process overwrote the resource) and bump the version.
- If the previous step passes, you commit the transaction. If not, you roll back the changes and return an error.
1def add_passenger(ride_id, passenger_id) do
2 ride = fetch_ride(ride_id)
3
4 Repo.transaction(fn ->
5 with true <- can_add?(ride, passenger_id),
6 :ok <- insert_passenger(ride, passenger_id),
7 :ok <- check_and_update_version(ride, ride.version + 1) do
8 :ok
9 else
10 {:error, :versions_dont_match} -> Repo.rollback(:version_conflict)
11
12 # Other error handling skipped
13 end
14 end)
15end
16
17defp fetch_ride(ride_id) do
18 Repo.get(Ride, ride_id) |> Repo.preload(:passengers)
19end
20
21def check_and_update_version(ride, new_version) do
22 query =
23 Ride
24 |> where(id: ^ride_id)
25 |> where(version: ^ride.version)
26
27 case Repo.update_all(query, set: [version: new_version]) do
28 {1, _} -> :ok
29 # No record found, so the version must have changed in the meantime
30 {0, _} -> {:error, :versions_dont_match}
31 end
32endNotice that we used a single update query here to verify the invariant. This works because Postgres prevents two or more transactions from making
conflicting updates by double-checking the where clauses. See the 'Read
Committed Isolation Level' section from the docs for more information.
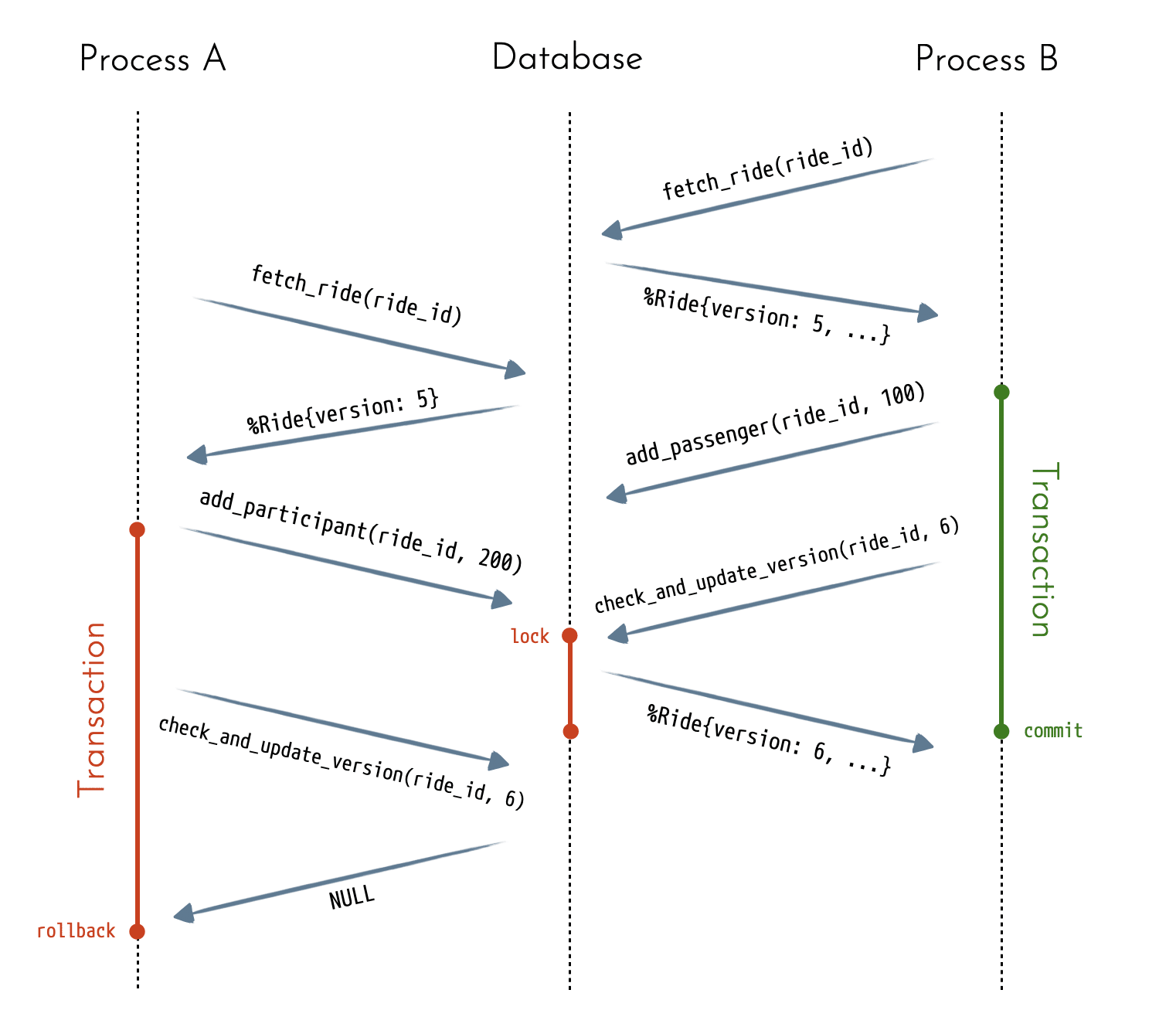
With optimistic locking, most of the work is done before we lock the resource.
In general, there's no need to use a transaction for the changes. If you can tolerate the state being inconsistent for a bit (which might also be a necessity in a distributed environment), instead of rolling back the transaction, you can use any other mechanism (like the saga pattern) to roll back the changes manually after detecting a conflict.
There's also nothing preventing you from making the business transaction span across multiple requests, giving you more flexibility (the only thing you need to do is pass the initial version id from request to request or save it somewhere).
Optimistic Locking — Alternatives to Version
The exact solution you use depends on the specific use case and the business logic behind it. While keeping the version number is a generic solution that works for every case (and is supported by
Ecto!), you can
make it better by using domain expertise.
In many cases, detecting a version conflict does not mean that we have to roll
back all the changes. In our example, we might keep a seats_left field on each
ride. Instead of verifying the version number (and potentially returning an
error for transactions that are correct from a business standpoint), we might
use that field for concurrency control. As long as the number is greater
than 0, we allow the update:
1defp decrease_seats_left(ride_id) do
2 query =
3 Ride
4 |> where(id: ^ride_id)
5 |> where([r], r.seats_left > 0) # Protects our invariant
6
7 case Repo.update_all(query, inc: [seats_left: -1]) do
8 {1, _} -> :ok
9 {0, _} -> {:error, :no_seats_left}
10 end
11endThis helps both the user experience and the performance of the system (since fewer queries are made).
Domain Knowledge is Key
Concurrency control might seem like a purely technical problem, but it's often not. Carefully analyzing the domain can lead to a far superior (and simpler) solution than relying on generic technical patterns. It's useful to:
- Carefully analyze the domain invariants.
- Make the invariants explicit in the codebase.
- Understand the chances of invariant violations.
- Understand the consequences of invariant violations.
You'll realize that the problem is not as black-and-white as we often think. Looking at it from the technical perspective, we see a strictly correct or incorrect state.
There will be certain cases where fully protecting all the invariants will be too hard or even harmful in real life. Plane overbooking is one example where the invariant is violated (to some degree) on purpose.
In these instances, designing processes to detect and deal with invariant violations might be better than trying to prevent those violations.
Events, CQRS, and Read and Write Models
When talking about aggregates, it's really easy to go down the DDD rabbit hole. You often see aggregates emitting events, or using separate data models for reads and writes. It's easy to start thinking about event sourcing.
Are those techniques useful? Of course!
The thing is that you don't have to solve all of them at once. It's also really hard to do most of the cases.
Designing well-isolated, event-sourced aggregates might seem easy on paper or when starting from scratch.
Most of the time, though, you'll be working on a messy codebase that you want to make better (which is fine!).
In such a scenario, building a fully event-driven aggregate is really challenging. Making sure that the events can cover all of the use cases and possible states is a lot of work.
But we can still benefit a lot just from making the aggregates a bit more explicit. Remember: the aggregate's job is not to emit events or use a write model, it's to protect domain invariants.
One of the best first steps you can do when refactoring an existing codebase is to find those invariants, put them in the code, and validate them in an explicit way.
Summary
In this article, we've learned that:
- A domain invariant always has to be true in a particular domain.
- Concurrent updates can lead to compromised invariants and Lost Update problems.
- Elixir processes can be used for concurrency control, but it's hard to do so with more than one node.
- Locking a resource before using it is called 'pessimistic concurrency control'.
- 'Optimistic concurrency control' is when we assume that it's safe to do an operation but still verify this just before committing changes.
Maybe most importantly, we've seen that domain knowledge is essential and that it's crucial to take small steps in the right direction instead of trying to do everything right the first time.
P.S. If you'd like to read Elixir Alchemy posts as soon as they get off the press, subscribe to our Elixir Alchemy newsletter and never miss a single post!








