


Let's talk about SPAs. It all starts from a blank page which is subsequently filled with HTML and JavaScript.
If we take PHP pages as an example, they already come bundled with the server, which is an advantage in terms of performance, right?
For situations like these, server-side rendering frameworks (such as Next.js) come to the rescue. They process the code on the server-side to pre-fill the HTML result page with something (if not the whole page) before it reaches the browser.
But is that all? Are there any other options, different paradigms or approaches to deal with this?!
In this article, we're going to explore a few alternatives brewing in the community regarding server-side rendering.
Do You Know What JAMStack Is?
Jamstack is a public effort to design an architecture that makes the web faster and scalable in terms of tools and workflows that us developers use today.
It's built on top of some core principles that include:
- Pre-rendering: in order to become a Jamstack-compliant developer, you'll need to dominate pre-rendering tools such as Gatsby and Next.js, and deliver your websites through prebuilt static pages.
- Decoupling: a famous concept that requires services and components to be clearly separated within your apps, reducing complexity and enhancing component independence.
You can read more on the movement here. Some of the things we'll discuss below are Jamstack-related, so give it a read if possible.
What if the Clients Stop Data Fetching by Default?
What do you mean? By default, most front-end frameworks today preach a complete separation between the front-end code and the back-end API that provides the endpoints that feed the client pages.
What if we take a step back and let the server deal with data fetching by allowing it to generate client interfaces (GraphQL-based, for example) that handle everything 一 from routing to ORM management.
Let's see an example with RedwoodJS as the framework of choice. Redwood is an opinionated, full-stack, serverless web framework that easily allows the development of JAMstack apps.
How Does It Work?
Rather than splitting the front and back-end sides of the application, Redwood aims to connect them through predefined GraphQL standards. Its goal is to be the full-stack framework you'd pick to create your SPAs. Take a look at the following graph:
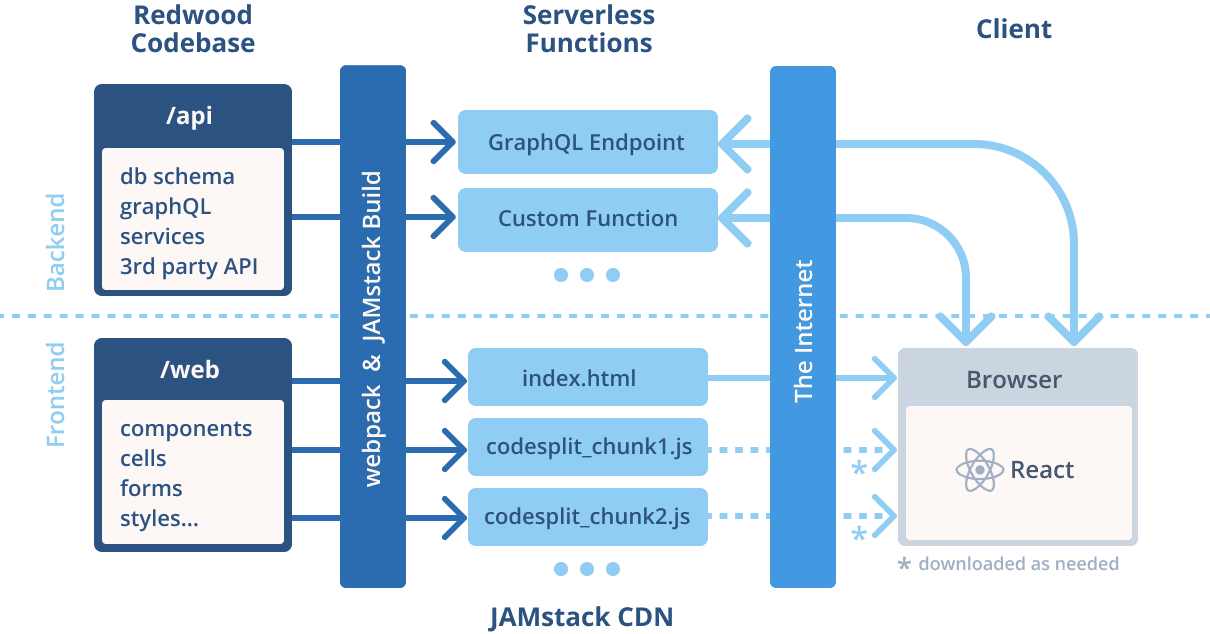
As you can see, both front and back-end worlds coexist within the same code repo. As we used to (and still) do with frameworks like Rails, .NET, etc. Yet, React is the front-end library of choice for the client-side.
Redwood divides itself into two main containers:
- /web: which contains the front-end stuff such as components, cells, forms, CSS, etc.
- /api: which contains the back-end API (built with GraphQL by default), as well as other optional services and lambdas.
The Main Parts
To achieve that, Redwood makes use of a bunch of features at its core. Like most of the frameworks, it comes with a custom routing system very similar to React Router, to take one example.
However, one of the most important parts refers to the concept of Cells. Redwood cells work as a scaffolded component that embraces the most common phases of an ordinary React component, such as retrieving data from the server, showing/hiding a loading placeholder, dealing with errors and success messages, and displaying the results in a proper listing component.
Take a look at the following cell example extracted from the official docs:
1export const QUERY = gql`
2 query USERS {
3 users {
4 id
5 name
6 }
7 }
8`;
9export const Loading = () => <div>Loading users...</div>;
10export const Empty = () => <div>No users yet!</div>;
11export const Failure = ({ message }) => <div>Error: {message}</div>;
12export const Success = ({ users }) => {
13 return (
14 <ul>
15 {users.map((user) => (
16 <li>
17 {user.id} | {user.name}
18 </li>
19 ))}
20 </ul>
21 );
22};
Since the components are attached to the GraphQL architecture, they must also embrace the gql schema structure within.
Each of the phases (loading, empty, failure, success) is automatically managed by Redwood. You only need to overwrite them with your code or remove them in case they're not needed.
Great! I got it. But, how does it work on the back-end side?
Redwood is GraphQL-based by default, which means that you'll need to define a GraphQL SDL. Usually, you need to write resolvers to let GraphQL understand where to route the incoming requests and deliver the outgoing responses.
Redwood simplifies this by doing it automatically. Based on your SDL specifications, services are auto-generated and each query or mutation is redirected to the specific service method. Take the following SDL as an example:
1export const schema = gql`
2 type Post {
3 id: Int!
4 title: String!
5 body: String!
6 createdAt: DateTime!
7 }
8
9 type Query {
10 posts: [Post!]!
11 post(id: Int!): Post!
12 }
13
14 input CreatePostInput {
15 title: String!
16 body: String!
17 }
18
19 input UpdatePostInput {
20 title: String
21 body: String
22 }
23
24 type Mutation {
25 createPost(input: CreatePostInput!): Post!
26 updatePost(id: Int!, input: UpdatePostInput!): Post!
27 deletePost(id: Int!): Post!
28 }
29`
It simply exposes two queries and three mutations to create a CRUD API over the posts' domain.
The generated services usually work directly with the database to retrieve and update the information, but you can customize the service with whatever actions you want:
1import { db } from 'src/lib/db'
2
3export const posts = () => {
4 return db.post.findMany()
5}
6
7export const post = ({ id }) => {
8 return db.post.findOne({
9 where: { id },
10 })
11}
12
13export const createPost = ({ input }) => {
14 return db.post.create({
15 data: input,
16 })
17}
18
19...
You can customize these functions to retrieve data from a database, other API services, serverless lambdas, etc. Whatever you prefer.
Each operation will also automatically provide successful results within the Success cell component that we've previously seen. As simple as that!
Redwood also offers other features like generators to avoid boilerplate code and forms to simplify the development of web forms along with React. For more on what you can do, please refer to its official docs.
Turbine Your SPAs Without JavaScript Frameworks
Have you ever found yourself uncomfortable with the "blinks" when transitioning from one SPA page to another? Have you ever heard about Turbolinks?
It is a small and lightweight library that coexists with your current server-rendered apps and makes navigating between pages faster by replacing the usual full page loads with partial page loads.
It works by intercepting the clicks within your page that target the same domain, i.e., the same server-based application. When the click is intercepted, the browser is prevented from requesting it and, instead, Turbolinks changes the browser's URL via history API.
Then it processes the request through an AJAX call and renders the response in the form of HTML.
It sounds simple, doesn't it? It is, in fact, simple.
Import the script into your head tag or add the npm package to your Node.js project, and you're ready to go:
1npm install turbolinksWhile you don't need to reload the whole page and, consequently, improve performance; you also need to pay attention to your code design. You can't rely on page loads to restart a state anymore and must be aware that your JavaScript global objects (like window) will retain the in-memory state. So, be careful.
Other than that, Turbolinks also provides awesome features like:
- Caching. It keeps a cache of the recently visited pages. If you go back to some of the history pages, it'll optimize the experience to make sure no call to the server is performed.
- On-demand Scripts. If the subsequent pages you navigate to need to load new
scriptelements, Turbolinks will handle that by appending them to theheadtag. That's great to have — loaded on-demand scripts — they enhance the overall performance.
Make sure to refer to the official docs for the API Reference and some nice examples.
What if We Don't Use JavaScript at All?
I know, that sounds disruptive, not to mention too contrarian, but there are some guys revisiting the past to create new stuff, like Phoenix LiveView, for example.
Some parts of the web community has critics debating the number of languages (or tools) needed to create something for the web. For example, is it really necessary to replicate the same JavaScript logic developed in the front-end to the Node.js back-end?
What if the state becomes fully controlled by the back-end rather than having agnostic APIs to provide endpoints for every change performed by the client?
Take the LiveView use case. LiveView is a server-state framework, which means that the state is kept under the server, and managed within it.
In other words, LiveView controls the state of the app — watching for changes made by the client and re-rendering the partial chunks related to that interaction back to the browser. The browser, in turn, will have a mechanism that understands these dynamics and updates the pages accordingly.
This means that we don't need to track down every single change happening to the client. We create the client HTML, program the server capabilities, and leave the change listening to the framework.
That's just one framework example (made in Elixir) out of many fermenting out there, such as Stimulus, and Laravel Livewire.
There are some work-in-progress Node.js ones, like Purview, but it's still in the early stages. Take this example from the official repo:
1import Purview from "purview";
2import * as Sequelize from "sequelize";
3
4const db = new Sequelize("sqlite:purview.db");
5
6class Counter extends Purview.Component<{}, { count: number }> {
7 async getInitialState(): Promise<{ count: number }> {
8 // Query the current count from the database.
9 const [rows] = await db.query("SELECT count FROM counters LIMIT 1");
10 return { count: rows[0].count };
11 }
12
13 increment = async () => {
14 await db.query("UPDATE counters SET count = count + 1");
15 this.setState(await this.getInitialState());
16 };
17
18 render(): JSX.Element {
19 return (
20 <div>
21 <p>The count is {this.state.count}</p>
22 <button onClick={this.increment}>Click to increment</button>
23 </div>
24 );
25 }
26}
Remember that this code exists within the back-end side of the application, which is really cool.
It resembles a bit of what we have with Redwood. The server code communicates directly with the database, has some well-defined phases (like the init state from React), and sets up a render method with the HTML output.
Chances are that Next.js is going to provide similar features in the near future, which would be groundbreaking for the Node.js universe.
Wrapping Up
Where to go from here? There are so many options that it's hard sometimes to choose a path... we know!
The first tip I'll give you is to measure and discuss what's the purpose of the app you're building. Not every framework and library may suit your app's needs every time.
Take the htmx library as an example. It is a super small ~8k dependency-free lib that helps you to easily perform AJAX calls and deal with WebSockets and SSE in your HTML. There's no need for a full SPA framework here.
You first import it and then, program your HTML elements to perform a POST request via AJAX updating the DOM once it's finished. For example:
1<!-- Load from unpkg -->
2<script src="https://unpkg.com/htmx.org@0.3.0"></script>
3<!-- have a button POST a click via AJAX -->
4<button hx-post="/clicked" hx-swap="outerHTML">Click Me</button>Chances are that you've never heard of some of the tools we've talked about here. Whatever the case, they represent strong alternatives that you can try and figure out if they fit your reality or not. Give them a try!
P.S. If you liked this post, subscribe to our new JavaScript Sorcery list for a monthly deep dive into more magical JavaScript tips and tricks.
P.P.S. If you'd love an all-in-one APM for Node.js or you're already familiar with AppSignal, go and check out AppSignal for Node.js.








