



Regardless of the tech stack used, many developers have already used Redis or, at least, heard of it.
Redis is specifically known for providing distributed caching mechanisms for cluster-based applications. While this is true, it's not its only purpose.
Redis is a powerful and versatile in-memory database. Powerful because it is incredibly super fast. Versatile because it can handle caching, database-like features, session management, real-time analytics, event streaming, etc.
However, when using it as a regular database, care must be taken for the in-memory part.
In this article, we're going to explore some of the most interesting nuances of Redis caching patterns, using Node.js as the environment to run some benchmark testing. Let's dive right into it!
Many Realms of Caching
You've heard the story before. Systems built on top of relational databases that start to grow quickly typically end up needing to remove some pressure off of them on the querying side in order to achieve better performance.
Caching, as a matter of physical implementation, can happen in many places within your systems: from the database layer itself to the application service layers and even as a remote distributed standalone service (just like Redis).
Let's explore each one of these types before moving on.
Type 1. Database-like Integration
Depending on the system design you're following, a combination of databases can help your system gain some processing performance.
For example, if you make use of CQRS to drive part of the load to a NoSQL database while reading data, and the other part to your relational database while writing it, that can be a form of database-like integration to achieve caching.
However, that's error-prone and takes loads of human effort to get it running, not to mention maintaining it.
Other databases, such as Aurora, go a little beyond and offer built-in mechanisms to enable caching at a database level. In other words, the application layer and clients don't need to know that caching exists because the database architecture itself takes care of the whole thing: adding and updating records as they arrive through internal replication logic.
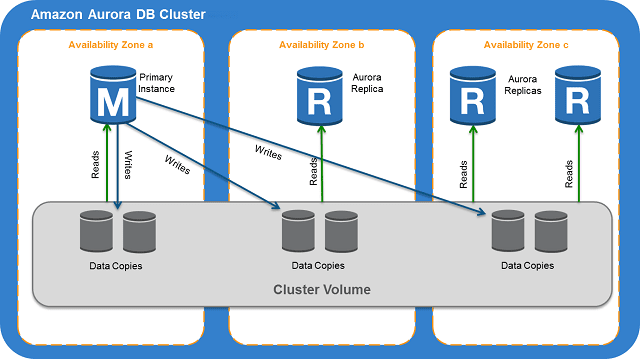
Obviously, there are some limitations in terms of available memory and data synchronization across the cluster instances. But, given the right use-case scenarios, that would be a powerful integration to consider.
Type 2. Local Application-based
Programmatic caches are one of the most common types being used because they're simply in-memory structures holding data.
Every programming language has its built-in or community-driven libraries to easily provide local caching in no time.
The major advantage is that it is super fast. The data is in memory, so your code can access it way faster than if it had to go through a TCP-like request to fetch it.
On the other hand, if you're working in a distributed microservice world (and I bet you are), each node of your cluster keeps its own versioned set of data that is not shared among the others. Not to mention all the data loss in case that particular node suddenly shuts down.
Type 3. Remote Caches (aka Redis)
Usually, this type of cache is also known as side cache, which means that it exists somewhere else that's not your application or database, as a service.
Because they work remotely, they had to be built to perform well under extreme circumstances. That's why they can usually handle huge amounts of data loads in a matter of milliseconds.
To choose such a type of cache is something to be done under discussion and considerations. For example, do you have details about your (or your provider's) network latency? Are you able to horizontally scale your Redis cluster?
Since there's communication from your application to the external world, there's got to be a plan for when things fail or get too slow.
Developers typically address this by mixing both local and remote caching strategies, which will give them a second barrier of protection for the edge-case scenarios.
Some Patterns for Caching
Once more, depending on your system requirements, the way you implement your caching can vary based on how reactive you want things to happen.
Let's take some time to break down the most common patterns for caching.
The Cache-aside Pattern
This is the most commonly used caching pattern. As its name suggests, it exists in a different side of the system architecture, apart from the application.
The application is responsible for the orchestration between the cache and the database as it considers the best. Take the following diagram:
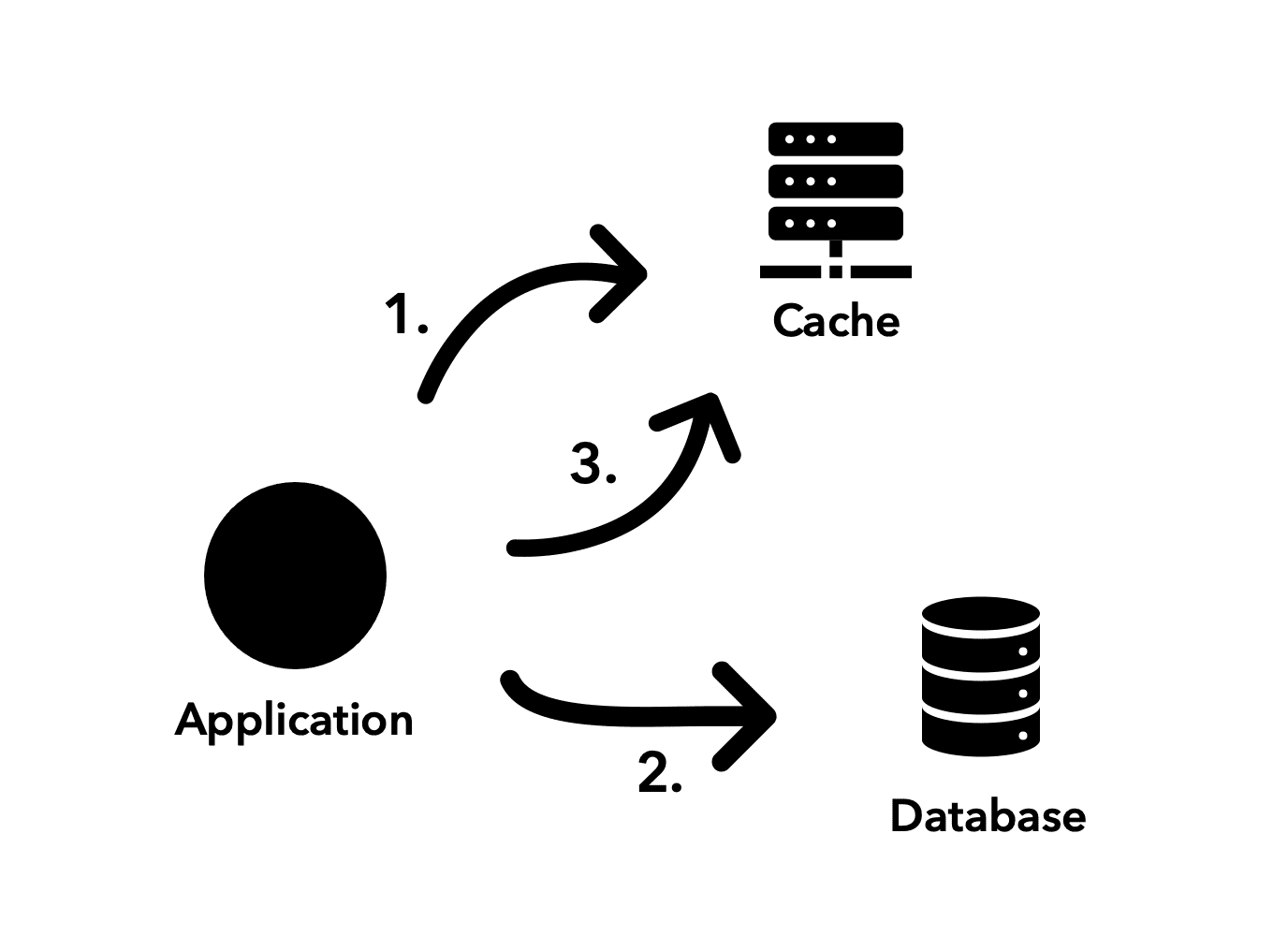
- The first step consists of checking the cache to see if the required data is there. If successful, the application returns the information to the client without calling the database.
- In case it's not, the application goes to the database to fetch the most up-to-date information.
- Finally, once it has the most recent version of the data, the application decides to write to the cache to make it aware as well.
There are many benefits to this strategy, such as the flexibility to deal with completely different data types in your cache and database. The database needs to be thoroughly thought-out since changes there can become too painful. The cache, however, gives you more freedom to play with more elastic data structures.
Be aware that the strategy demonstrated in the image above can be troublesome in case you write data to the database and the cache update fails. For situations like this, it's important to have a second plan like a TTL (time to live) setup, in which developers establish a timeout for invalidating particular data in the cache. This way, when a cache data update fails, the application won't handle outdated data for too long.
The Write-Through Pattern
This pattern takes the opposite approach to the cache-aside. Here, the application first writes to the cache when any change is detected before going to the database.
That's where it gets its name from since it goes through the cache layer before proceeding to the final database write.
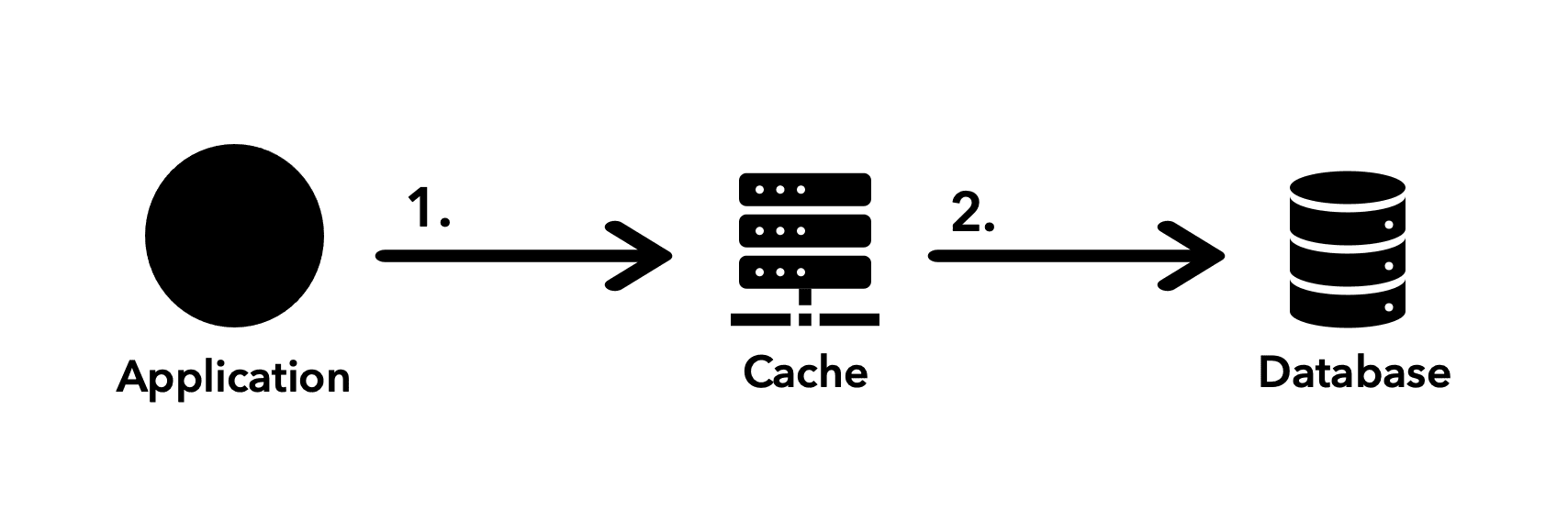
You must be careful when modeling such a strategy, especially for situations in which the database write fails.
For such scenarios, you can either establish a retry policy to try saving to the database at all costs or throw a transactional error that would rollback the previous cache write.
Just be aware of the consequential increase in the overall processing time of each flow.
A Walkthrough with Node.js
We'll be running a benchmark test on a Node.js application that will expose two API endpoints: one to handle cached data and another with no cache.
The goal is to demonstrate how to quickly configure your project to make use of the cache-aside pattern while benchmarking the two endpoints for you to see the enormous performance gains Redis can add to a REST API.
Project Setup
You can follow the official quickstart guide to get started, which uses the following commands:
1wget http://download.redis.io/redis-stable.tar.gz
2tar xvzf redis-stable.tar.gz
3cd redis-stable
4make
5make-install
After that, you may run the command redis-server to start the server and see the following screen response:
Next, create a folder named redis-app—the name of our Redis with Node application—and cd into it.
Then, run the following commands to initialize the Node project and add npm dependencies:
1npm init
2npm install express redis axiosFinally, create a new file called index.js at the root of the project and insert the following code into it:
1const axios = require("axios");
2const express = require("express");
3const redis = require("redis");
4
5const app = express();
6const redisClient = redis.createClient(6379); // Redis server started at port 6379
7const MOCK_API = "https://jsonplaceholder.typicode.com/users/";
8
9app.get("/users", (req, res) => {
10 const email = req.query.email;
11
12 try {
13 axios.get(`${MOCK_API}?email=${email}`).then(function (response) {
14 const users = response.data;
15
16 console.log("User successfully retrieved from the API");
17
18 res.status(200).send(users);
19 });
20 } catch (err) {
21 res.status(500).send({ error: err.message });
22 }
23});
24
25app.get("/cached-users", (req, res) => {
26 const email = req.query.email;
27
28 try {
29 redisClient.get(email, (err, data) => {
30 if (err) {
31 console.error(err);
32 throw err;
33 }
34
35 if (data) {
36 console.log("User successfully retrieved from Redis");
37
38 res.status(200).send(JSON.parse(data));
39 } else {
40 axios.get(`${MOCK_API}?email=${email}`).then(function (response) {
41 const users = response.data;
42 redisClient.setex(email, 600, JSON.stringify(users));
43
44 console.log("User successfully retrieved from the API");
45
46 res.status(200).send(users);
47 });
48 }
49 });
50 } catch (err) {
51 res.status(500).send({ error: err.message });
52 }
53});
54
55const PORT = process.env.PORT || 3000;
56app.listen(PORT, () => {
57 console.log(`Server started at port: ${PORT}`);
58});
The code makes use of an external mock API, the JSONPlaceholder, which is very useful for API data faking. In this case, we're going to retrieve some fake user's data.
Pay attention to the code line where we're creating the Redis client. The port is usually the default, 6379, but make sure to check it at the Redis server logs that we've seen in the previous image.
There are two endpoints. The first will basically fetch data from the user's API with no cache in-between. This way, you may see how much overload subsequent HTTP calls can add to an application's overall performance.
The second endpoint is the one that's always checking for the given data within Redis. If the data's key is present, we skip the API call and retrieve the data directly from the cache, otherwise, we'll make sure to fetch the information and store it to Redis right away.
Pretty simple, isn't it? Let's move on to the benchmark code. First of all, let's add a Node library that will help us with that. We'll be using the api-benchmark tool because it's powerful and comes with the ability to generate visual reports for the benchmarks.
Run the following command to add it as a dependency:
1npm install api-benchmarkThen, create another file called benchmark.js and add the following code to it:
1var apiBenchmark = require("api-benchmark");
2const fs = require("fs");
3
4var services = {
5 server1: "http://localhost:3000/",
6};
7var options = {
8 minSamples: 100,
9};
10
11var routeWithoutCache = { route1: "users?email=Nathan@yesenia.net" };
12var routeWithCache = { route1: "cached-users?email=Nathan@yesenia.net" };
13
14apiBenchmark.measure(
15 services,
16 routeWithoutCache,
17 options,
18 function (err, results) {
19 apiBenchmark.getHtml(results, function (error, html) {
20 fs.writeFile("no-cache-results.html", html, function (err) {
21 if (err) return console.log(err);
22 });
23 });
24 }
25);
26
27apiBenchmark.measure(
28 services,
29 routeWithCache,
30 options,
31 function (err, results) {
32 apiBenchmark.getHtml(results, function (error, html) {
33 fs.writeFile("cache-results.html", html, function (err) {
34 if (err) return console.log(err);
35 });
36 });
37 }
38);
We'll be running two separate executions for each of the scenarios: one with no cache, and the other with Redis in the middle.
The testing is going to consider a load of 100 requests per test, which is not ideal for production-ready purposes, but more than enough to demonstrate the power of Redis. You may re-run the tests later with more requests to see how the gap increases.
Run the Node application via node index.js command. Pay attention to the logs to see if any error shows up.
Then, in a new Terminal window, run the following command to start the benchmark tests:
1node benchmark.jsIf everything went well, you may see two new HTML files under the root folder of your project. Open them in a web browser and similar results to what's shown below, may be displayed:
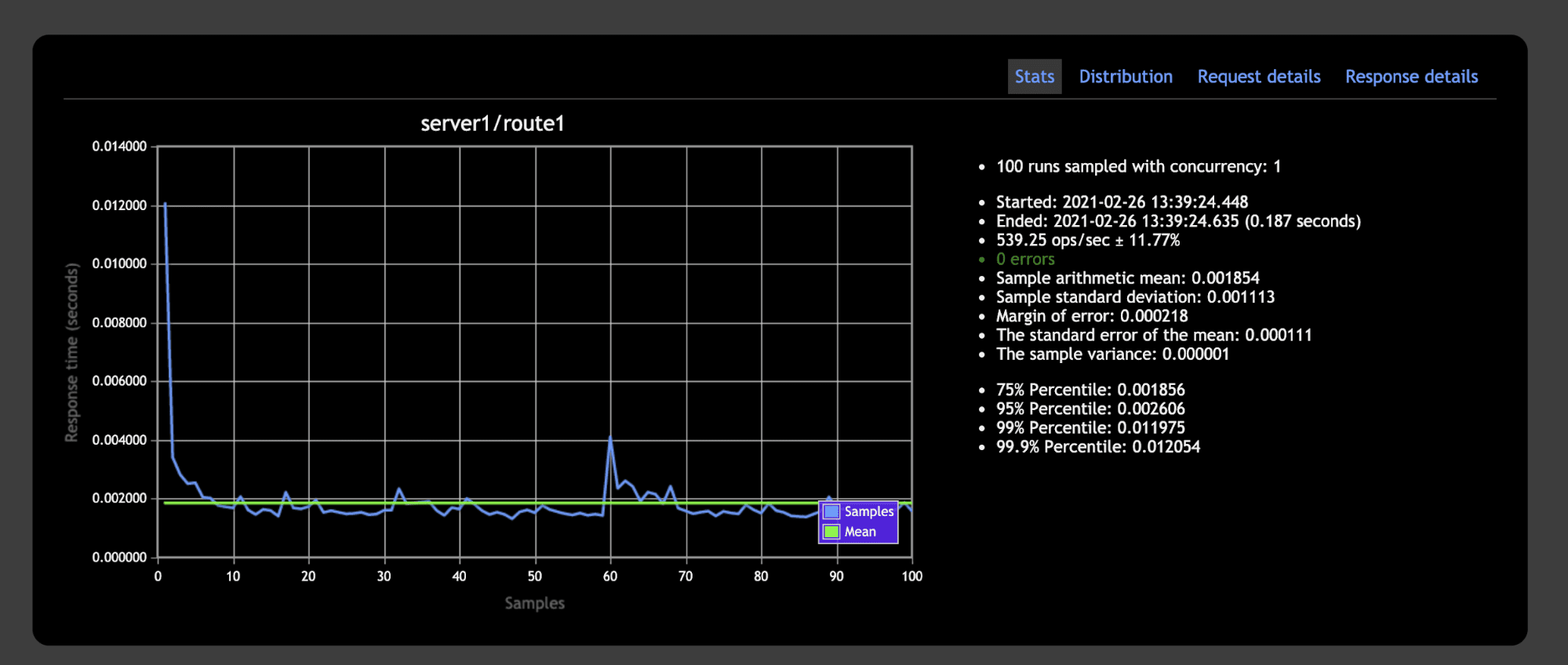
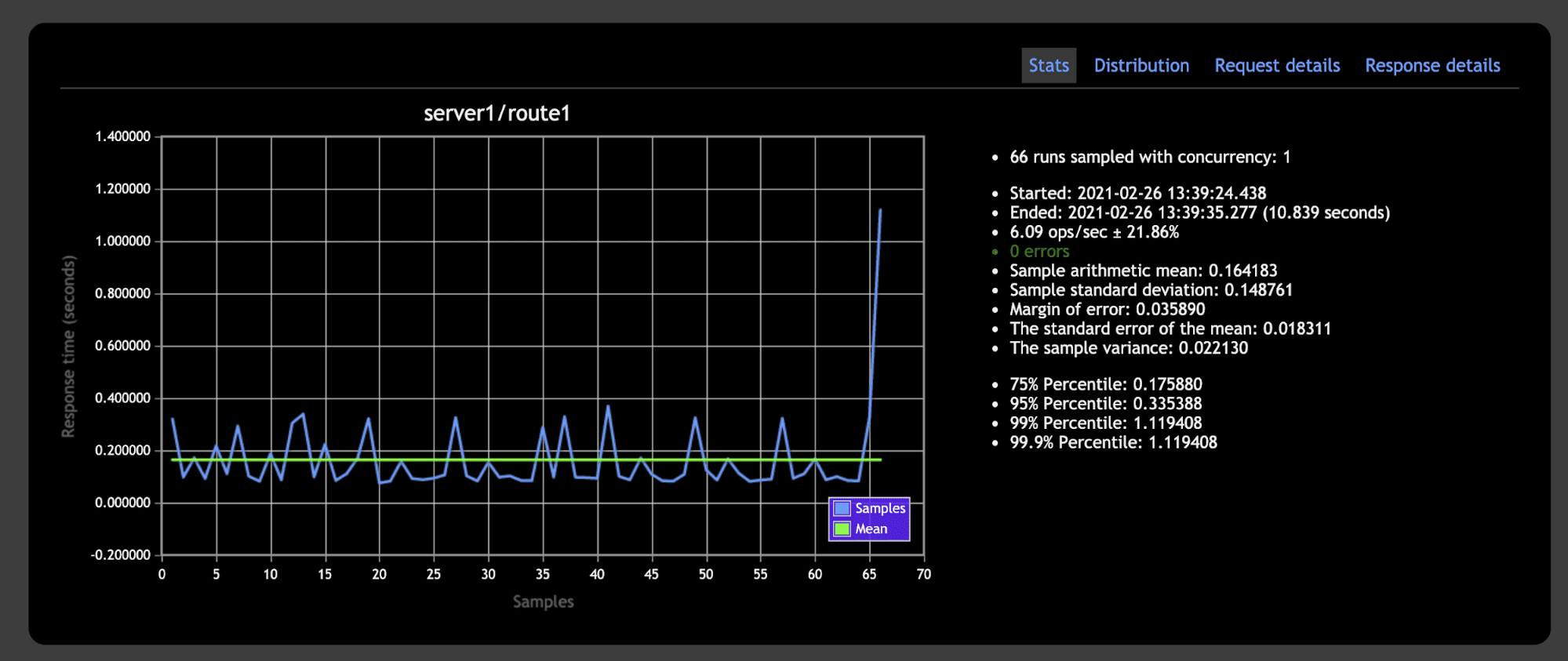
Take a look at the statistics generated at the right-side panel. The non-cached API ended the tests in ~11 seconds, while the Redis-cached one finished in just ~0.19 seconds.
That's an incredible difference if you think about applications that receive tons of requests per second in the real world.
Wrapping Up
There are other caching patterns that are used by developers, however, to keep things simple, we're just focusing on the most popular and powerful ones.
Modern applications can't live without a minimum amount of performance. As time goes on, this requirement gets more and more strict as the complexity and amount of requests hitting applications increase exponentially.
Redis is just one out of many great options of caching out there. Indeed, it is powerful, flexible, and loved by many companies and tech communities.
As homework, I'd recommend you implement the second caching pattern, the write-through, to check the difference compared to the cache-aside in terms of performance. Good luck!
P.S. If you liked this post, subscribe to our new JavaScript Sorcery list for a monthly deep dive into more magical JavaScript tips and tricks.
P.P.S. If you'd love an or you already know AppSignal, go and check out the AppSignal APM for Node.js.








